

컴퓨터는 계산을 위해 태어났다.
복잡한 계산을 위해선 값과, 값을 저장할 수 있는 기능이 필요했다.
컴퓨터가 다룰 수 있는 값은 본질적으로 010101과 같은 숫자로 이루어져 있어야 하는데,
인간의 편의를 위해 단순 정수 말고도 좀 더 다양한 형식의 자료들을 연산할 필요가 있었다.
그래서 이진수로 다양한 값의 종류를 표현했는데, data의 type에 따라 저장될 공간의 크기와 형식이 다르게 되었다. 이러한 자료의 형태를 자료형이라고 부른다.
이러한 자료형은 크게 기본형과 참조형으로 나뉘게 되는데,
기본형은 말 그대로 컴퓨터가 표현할 수 있는 문자, 정수, 실수 등의 기본적인 data type이고
참조형은 내가 저장하고 싶은 데이터의 주소값을 가지고 있는 type이다.
자바에서는 보통 객체의 인스턴스가 저장된 주소값을 참조형 변수가 가지고 있게 된다.
기본형은 저장할 값을 "data"의 종류에 따라 구분하므로 자료형 "data type"이라는 표현을 쓰고, 참조형은 객체의 종류에 따라 구분되므로 "type"이라는 표현을 사용한다.
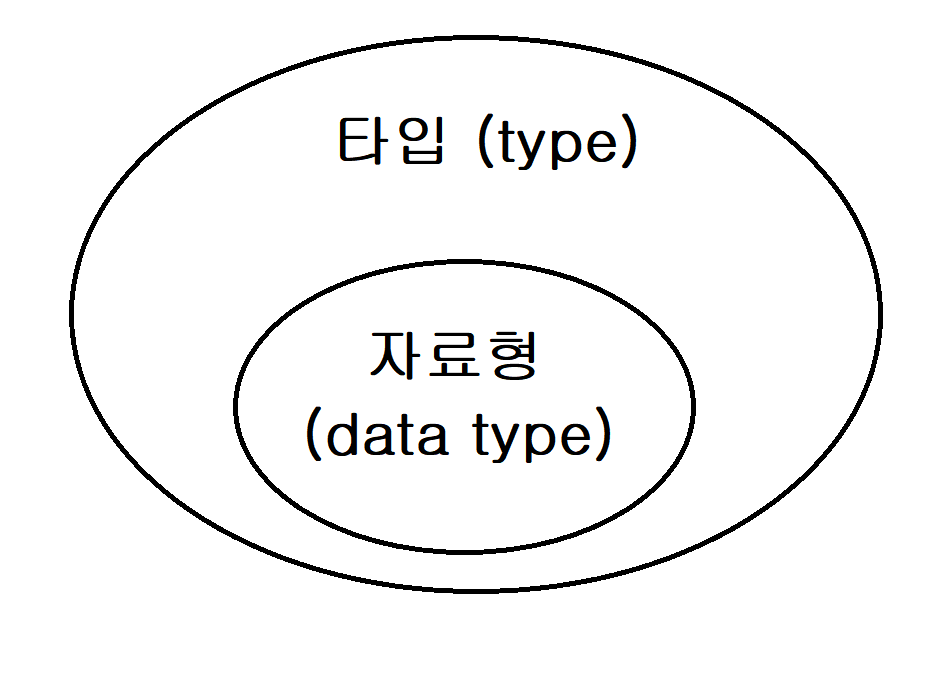
기본형은 그 종류에 따라 크기가 다양하지만, 참조형은 4 byte정수의 객체 주소를 저장한다.
1. Primitive Type
기본형 변수는 실제적인 값을 저장한다. 기본적으로 논리형(boolean), 문자형(char), 정수형(byte, short, int, long), 실수형(float, double)로 나뉘며 8개이다.
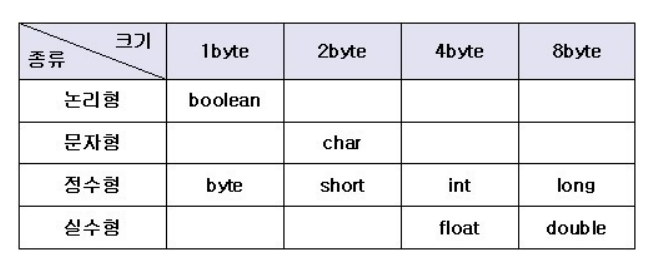
이 중 "맞냐", "틀리냐" 만을 따지는 논리형 boolean을 제외한 7가지 유형은 서로 연산과 변환이 가능하다.
이는 후술하겠다.
boolean은 단지 ture와 false 두 가지 값만을 표현할 수 있으므로, 컴퓨터의 최소 정보 처리 단위인 1 byte만을 사용한다.
문자형 char는 숫자를 이용해 문자를 표현한다. 거창해보이지만, 그냥 어떤 숫자는 어떤 문자를 표현하겠다는 약속을 미리 정해두고 사용하는 것이다. 자바에선 이런 약속 중 2 byte 문자 체계인 "유니코드"를 사용하므로, 2 byte를 사용한다.
정수형과 실수형은 다양한 크기의 자료형이 제공되는데, 메모리를 아끼려면 저장하려는 숫자의 표현 범위를 고려해서 잘 선택하면 된다.
1.1 자료형과 효율?
자바의 정석에선 CPU가 int를 가장 효율적으로 처리한다고 한다.
자세한 설명이 없어 찾아보니, JVM의 Operand는 최소 4 byte인 int 단위로 연산자를 처리하므로, 계산 효율만 따지자면 4byte인 int가 효율이 좋다고 한다. JVM 명세에 명확히 적혀있지는 않다. (내가 못 찾은 것일 수도 있다)
바이트 코드를 열어보자. 아래와 같은 클래스가 있을 때

바이트 코드는 아래와 같다.
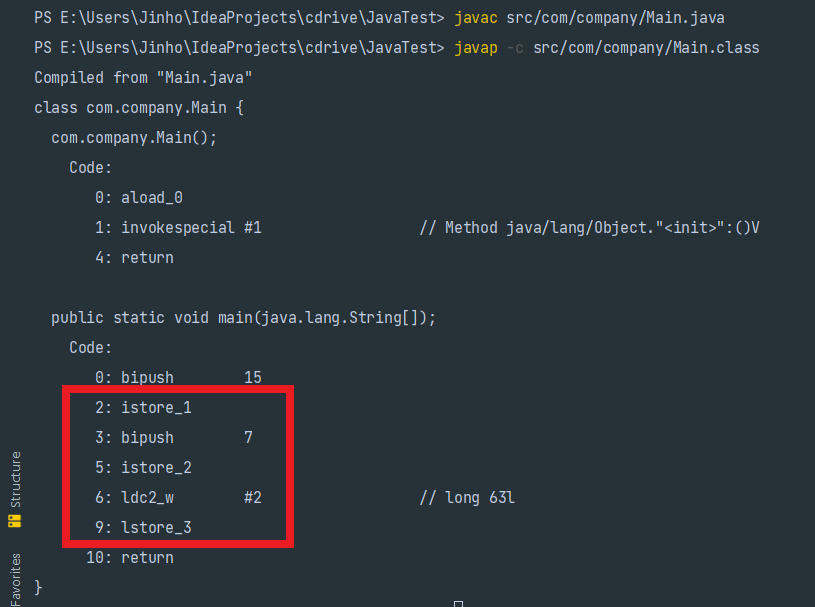
main 메서드 쪽을 보면 int와 short 모두 istore를 사용했는데, 이 istore가 int 크기라고 한다. 그래서 short를 int로 변환하는 시간이 소모되므로, 그냥 int를 쓰는게 시간 효율적으로 낫다고 한다.
사실 웹 개발에 주로 쓰이는 자바 같은 언어를 사용하며 저장 공간 효율을 극도로 신경 쓸 일이 많지 않을 것 같으므로, 웬만하면 short나 byte 대신 int를 쓰는 것도 나쁘지 않을 것 같다.
참고로 long은 lstroe이라는 long strore를 사용했다. long은 그대로 long을 쓰면 될 것 같다.
1.2 자료형의 표현 범위
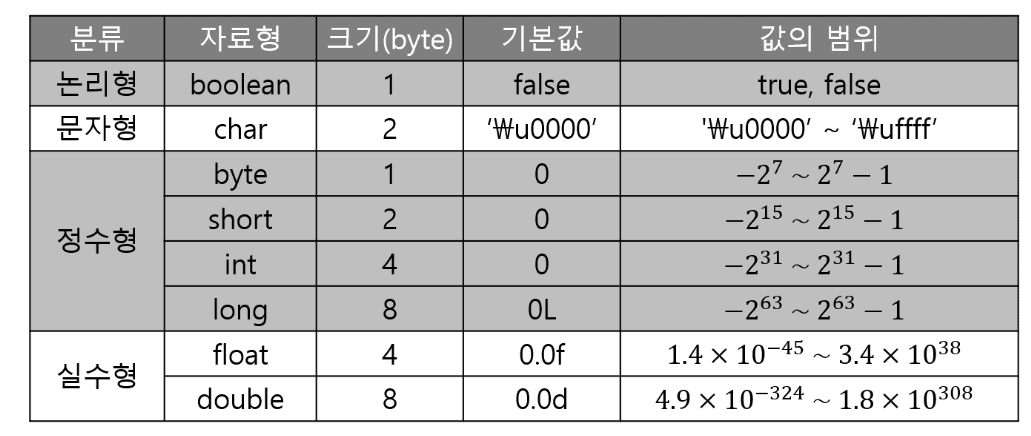
각 자료형들은 자신이 표현 가능한 범위를 가지고 있다.
최소 표현 가능 값 부터 최대까지는 자료형의 크기와 동일하다.
정수형이나 실수형은 표현 범위를 고려하며 자료형을 선택하면 된다.
표현 가능한 범위가 넘어가게 되면, 계량기처럼 숫자가 넘어간다.
그러니까 자료형의 최대값에서 값을 더 더하면 최소값으로 넘어가게 되고, 최소값에서 빼면 최대값으로 넘어가게 된다.
그래서 기본형을 사용할땐, 꼭 그 변수가 가질 수 있는 값의 범위를 고려해야한다.
쉬운 이야기 같지만, 가끔 이와 관련한 오류가 발생하면 찾기가 굉장히 어렵다.
예를 들어 친구의 팀이 개발을 하던 중 js의 정수 값의 범위가 java의 int 표현 가능 범위보다 몇 바이트 정도 작아서 값이 잘리는 오류가 발생했었다. 이런 오류는 원인을 찾기 정말 어려우므로 항상 조심해야 한다.
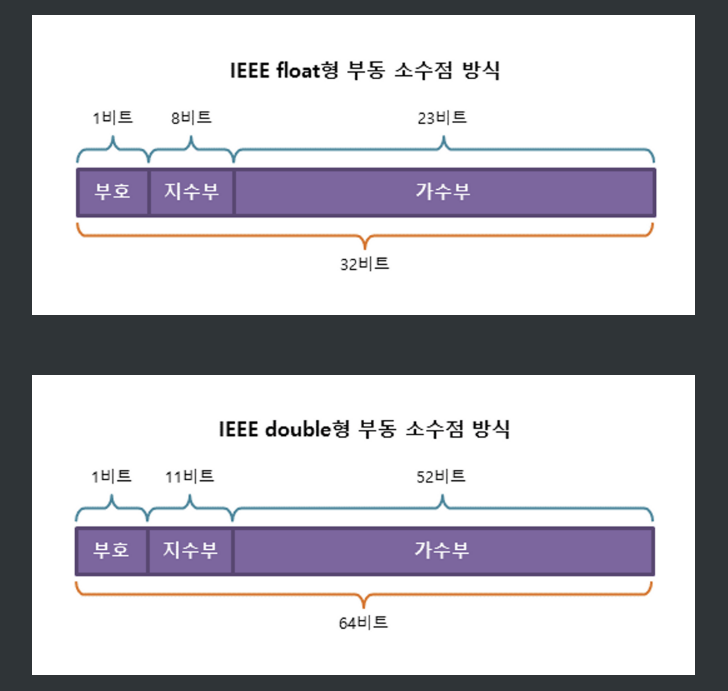
실수형의 경우, 01010101 과 같은 이진수들로 실수를 표현하려다 보니 지수부와 가수부를 나우어 저장하게 되었다.
이 점 때문에 정확히 표현할 수 없는 값들도 있고, 정밀도가 중요해진다.
정밀도는 소수점 아래로 얼마나 표현 가능한지에 대한 용어인데, 정밀도가 높을 수록 소수점 아래로 더 많이 저장하면서 더 "자세히" 값을 표현할 수 있게 된다.

1.3 기본형의 Type 변환
(형변환 선요약)
1. boolean 을 제외한 나머지 7개의 기본형은 서로 형변환이 가능하다.
2. 기본형과 참조형은 서로 형변환 할수 없다.
3. 서로 다른 타입간 연산에선 형변환이 필요하다.
4. 값의 범위가 작은 타입에서 큰 타입으로의 형변환은 명시하지 않아도 자동 형변환이 수행된다.
자료형은 각자 다른 저장 방식, 표현 범위 등을 가진다.
그렇다면 서로 다른 자료형끼리의 연산은 어떻게 수행될까?
바로 연산이 수행되는 두 타입 중 표현범위가 더 넓은 타입으로 자료형을 변환해서 타입을 일치시킨 다음에 연산을 수행한다.
이런 변수나 리터럴의 타입을 다른 타입으로 변환하는 것을 '형변환' 혹은 Casting이라고 부른다.
boolean을 제외한 7개의 기본형은 서로 다른 자료형으로 변환될 수 있다.
변환하는 방법은 간단하다. 괄호에 변환할 타입을 넣어주면 되는데 이를 형변환 연산자라고 부른다.

(참조 변수의 Casting은 뒤에서 보이겠다)
사진을 보면 형변환 연산자를 이용해 간단하게 자료형을 바꿔줄 수 있다.
하지만, 타입 변환시 주의해야 할 점이 있다.
바로 표현 범위나 저장 크기에 따라 변환 이후 값이 변화할 수 있다는 점이다.
예를 들어, 실수형인 float 타입을 정수형인 int 타입으로 변환할 때 소수점 이하의 값은 버림 처리됨에 주의해야한다.
그리고 사이즈가 큰 타입에서 작은 타입으로 변환될 때는 값의 loss가 발생한다.
예를 들어 4 byte인 int 값 384은 256 + 128로 이루어져 있다.
이 숫자를 크기가 1 byte인 자료형 byte로 형변환 하는 경우, 아래 그림과 같이 수용 가능한 범위만 남겨 128이라는 값을 갖게 된다.
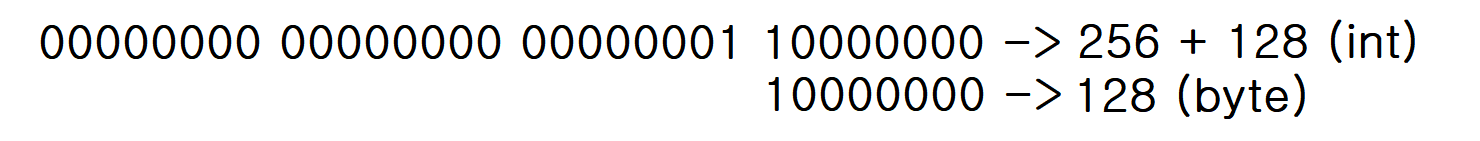
크기가 작은 자료형에서 큰 자료형으로 변경할 때는 편하게 값을 받아낸 다음,
2의 보수법에 의해 남은 공간을 양수의 경우 0으로, 음수의 경우 1로 채워준다.
실수형끼리 변환하는 경우, 지수와 가수를 나누어 생각해야한다.
지수의 경우 바뀌기 이전 자료형의 기저값을 뺀 다음, 바꾼 이후의 기저값을 더해준다.
float의 기저값은 127 이고, double 의 기저값은 1023 이다.
그 외엔 정수형끼리의 변환과 동일하다.
예를 들어 어떤 float 값의 지수부가 1001 0100라면,
double로 변환하는 경우 127을 빼고 1023을 더해 100 0001 0100이 된다.
가수 부분은 일반 정수끼리의 변환과 달리, 뒷 부분만 살아남는게 아니라 뒷 부분이 잘린다.
예를 들어 double을 float으로 변환한다면 double의 52자리 중 23자리만 저장되고, 나머지는 버려진다. 다만 버려지는 과정에서 가수의 24번째 자리에서 반올림이 발생한다. 따라서 24번째 숫자가 1인 경우 23번째 자리의 값이 1만큼 증가하게 된다.
이런 반올림 때문에 아예 같은 값을 float과 double에 저장해도 실제론 다른 값을 저장하게 될 수도 있다.
그리고 float 범위를 넘어가는 값을 float으로 바꾸는 경우 +-무한대 혹은 +-0을 결과로 얻게 된다.
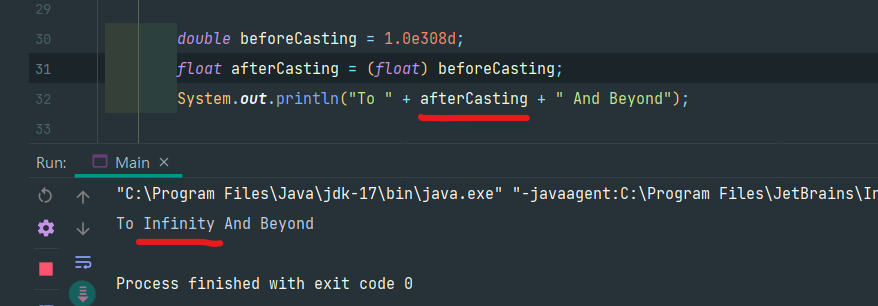
(java의 실수형엔 Infinity가 있다 => Infinity in Java : https://www.baeldung.com/java-infinity)
한편 정수형을 실수형으로 바꿀 때는 간단하게 정규화를 거쳐 저장하면 된다.
단, float의 경우 표현하는 범위가 짧기 때문에 약 8자리 이상의 int를 변환하는 경우 loss가 발생할 수 있다. 큰 int를 실수형으로 변경할 때는 double로 변경해야 한다.
실수를 정수형으로 변환할 때는 소수점 이하 값들이 모두 버려진다. 단순히 버려지고 반올림 되지 않는다.
1.4 자동 형변환 (Promotion)
이런 형변환들은 서로 다른 타입간 연산에서 컴파일러에 의해 자동으로 이루어질 때도 있다.
값을 할당할 때, 우변의 값이 변수 자료형에 충분히 저장될 수 있다면 따로 형변환을 명시하지 않아도 알아서 적용된다.
이를 자동 형변환, Promotion이라고 부른다.
반대로 변수가 저장할 수 있는 값의 범위보다 우변의 값이 더 큰 경우 에러가 발생한다.
따라서 이런 경우 명시적으로 형변환을 지정해줘야 한다.
서로 다른 두 타입간의 연산에서는 두 타입 중 표현범위가 더 넓은 타입으로 형변환해서 타입을 일치시킨 다음에 연산을 수행한다.
이는 최대한 값 손실의 가능성을 줄이기 위해서이다.
예를 들어 1.0과 정수 3을 더한다면 정수 3은 double로 형변환 된다.
이런 연산 과정에서의 형변환을 산술 변환이라고 한다.
컴파일러가 자동으로 형변환을 수행할 때 기준을 알아보자.
컴파일러는 값들을 최대한 보존할 수 있는 방향으로 자동 형변환을 수행한다.
따라서 서로 다른 두 타입 중 표현 번위가 더 넓은 타입으로 형변환 하려 한다.
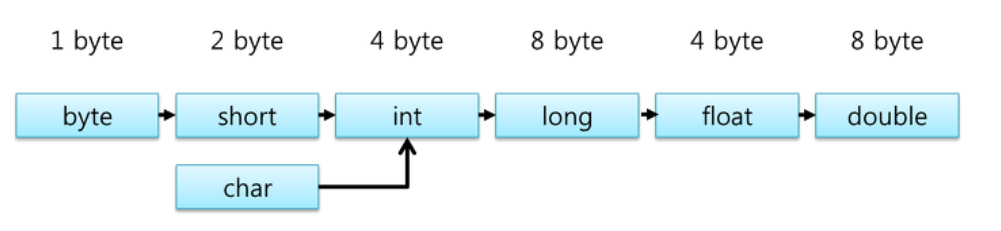
그림에서 왼쪽에서 오른쪽 방향으로는 자동 형변환이 일어나고,
반대 방향은 형변환 연산자를 명시해줘야 한다.
실수형은 값의 크기가 같더라도 표현 범위가 더 크기 떄문에, float와 double이 가장 오른쪽에 위치한다.
char는 0 ~ 2^16 - 1, short는 -2^15 ~ 2^15 -1로 범위가 서로 다르다. 서로간의 형변환은 값 손실이 발생할 수 있고, 자동 형변환이 수행되지 않는다.
형변환에 대해 정리하자면
1. boolean 을 제외한 나머지 7개의 기본형은 서로 형변환이 가능하다.
2. 기본형과 참조형은 서로 형변환 할수 없다.
3. 서로 다른 타입간 연산에선 형변환이 필요하다.
4. 값의 범위가 작은 타입에서 큰 타입으로의 형변환은 명시하지 않아도 자동 형변환이 수행된다.
2. Literal과 Constant Pool
리터럴은 우리가 잘 아는 '상수' 개념이다. 값 그 자체를 의미하며, 기본형들의 type을 모두 가지고 있으면서 문자열을 표현하는 문자열 리터럴도 가지고 있다.
우변에 위치한 12, 34의 값 그 자체를 리터럴이라고 부른다.
int onetwo = 12;
final int THREE_FOUR = 34;
이러한 리터럴들은 클래스 파일 내의 Constant Pool에 저장되고, 런타임시 Runtime Constant pool에 저장된다.
그리고 문자열 리터럴은 캐싱하여 재활용 할 수 있는데,
이런 문자열 리터럴이 저장되는 곳을 String Constant Pool이라고 한다.
예를 들어 "테스트"라는 문자열 자체를 Pool에 저장한 다음
똑같은 값을 가진 문자열이 필요해지면, 새로 만들지 않고 Pool에서 가져다가 쓰는 것이다.
3. Reference Type
래퍼런스 타입은 참조형이라고 부른다. 4 byte의 정수 주소값을 저장하는 변수로, Heap 영역에 존재하는 객체의 인스턴스의 주소값을 저장한다.
인스턴스를 직접 저장하려고 하면 당연히 매우 무거우므로, 주소만을 저장한다.
클래스의 이름이 곧 자료형처럼 쓰이고, 참조형 변수는 자신의 하위 클래스 인스턴스까지도 참조 가능하다.
이는 자바의 강력한 기능 중 하나인 다형성에 의해 제공된다.
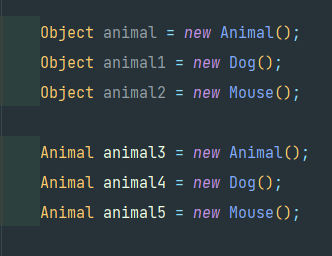
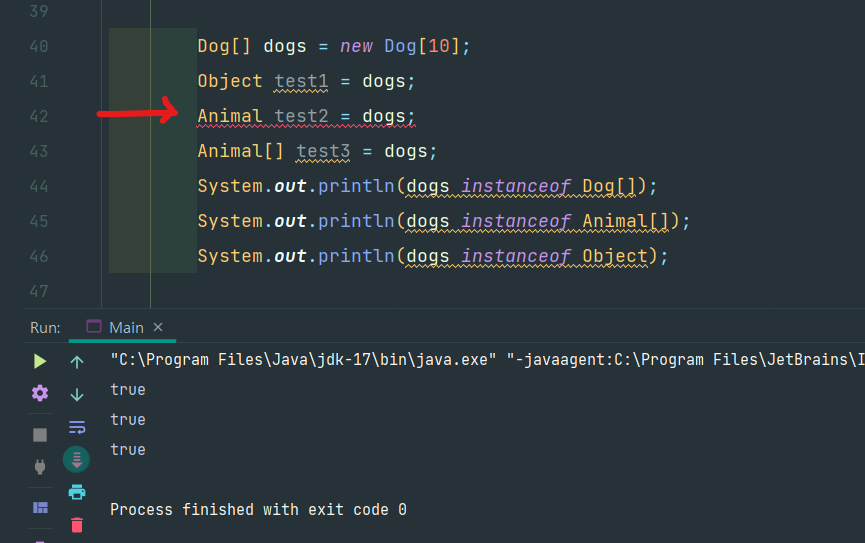
Object 클래스는 모든 클래스의 최상위 클래스이고, Dog와 Mouse는 Animal의 하위 클래스이다.
위의 그림과 같이 Object 참조 변수로 Animal, Dog, Mouse 인스턴스를 참조할 수 있다.
그리고 Animal 참조 변수로 Animal, Dog, Mouse 인스턴스를 참조할 수 있다.
참조형 변수를 이용하면, 선언에 쓰인 클래스와 그 상위 클래스가 가진 맴버나 메서드를 호출할 수 있다. (접근 제어에 따라)
참조변수의 타입에 따라 사용할 수 있는 맴버나 메서드의 갯수가 달라진다고 표현한다.
하위 클래스는 상위 클래스를 확장한 형태인데, 하위 클래스로 참조하면, 확장된 맴버나 메서드 호출이 가능한 것이다.
하위 클래스에서 맴버 변수가 중복 정의된 경우 참조변수가 가진 맴버 변수를 호출하고,
하위 클래스에서 메서드가 재정의된 경우 인스턴스가 재정의한 메서드가 호출된다.
3.1 Reference Type의 Casting
이런 점들의 이해는 참조형 변수들간의 형변환인 Casting의 이해에 좋다.
자바의 강력한 다형성 기능은 인스턴스를 참조하는 참조형 변수 선언에 인스턴스와 동일한 타입 뿐만 아니라 상위 클래스 또한 허용한다.
자바의 다형성 덕분에 상위 클래스 타입의 참조변수로 하위 클래스의 인스턴스를 참조할 수 있다.
어떤 인스턴스는 해당 인스턴스가 가진 타입의 참조 변수 뿐만 아니라,
상위 클래스 타입의 참조 변수로도 참조할 수 있는 것이다.
Castring은 하위 클래스에서 상위 클래스로만 허용되는데,
위에 언급된 점들을 생각해보면 이해하기 쉽다.
이를 업 캐스팅이라고 한다. (반대는 다운 캐스팅)
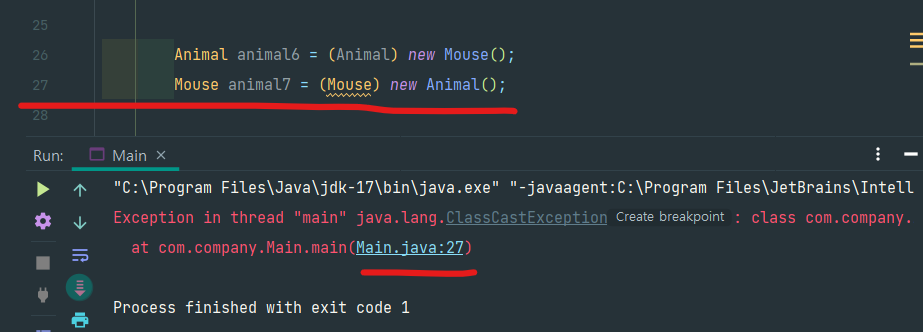
위의 그림과 같이 다운 캐스팅 시도시 ClassCastException이 발생한다.
4. Java의 Array는 객체다
배열은 한가지 타입의 데이터들을 메모리상 연속적으로 배치해 놓은 데이터 묶음이다.
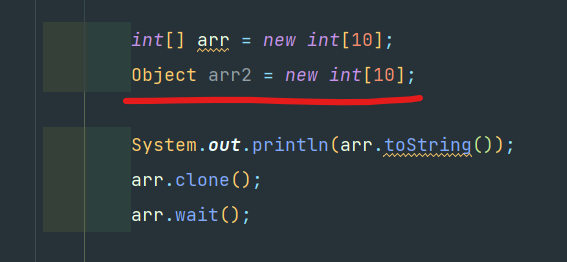
Java에서의 배열은 객체이다. 직접적으로 Object를 상속하는 코드를 확인하고 싶었으나, 찾을 수 없었지만
오라클의 도큐먼트나 다른 자료들에 따르면 객체로 취급되어 Object의 메서드 호출이 가능하다.
또한 Cloneable과 java.io.Serializable 인터페이스를 구현한다.
상속 관계가 있는 클래스의 배열은 그 관계를 유지한다. 예를 들어 Animal 클래스가 있고 그를 상속 받는 클래스들에 대해 아래와 같은 관계가 성립한다.
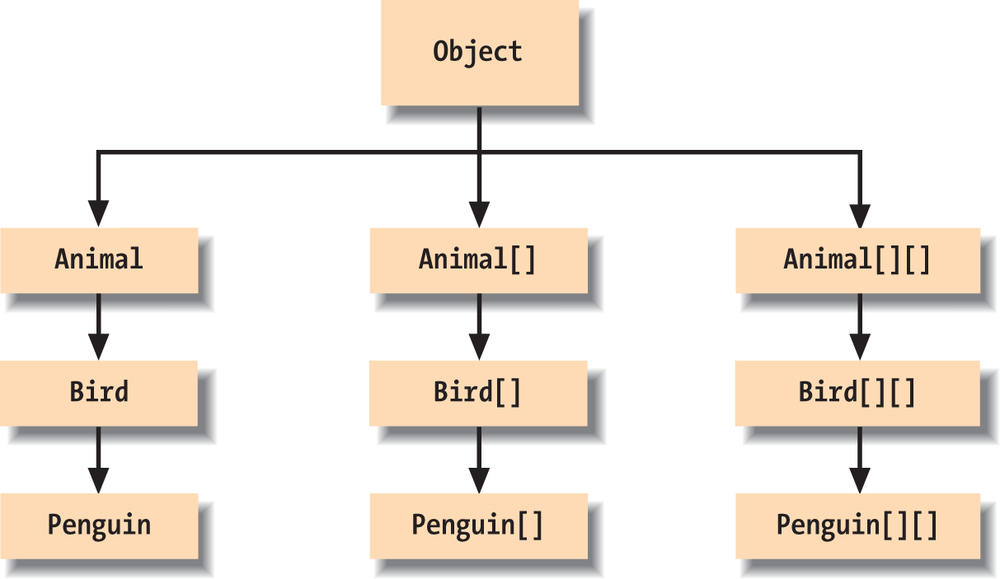
코드로 확인해봐도 그렇다.
5. Type Inference와 Java 10 Var
자바 컴파일러는 변수의 초기화 단계나, 다이아몬드 연산자 (꺽쇠), 제네릭을 사용할 때 타입을 추론한다.
자바의 추론 알고리즘은 모든 인수와 함께 작동하는 가장 구체적인 유형을 찾으려고 시도하여 반환한다.
Java 10에선 지역변수 유형 추론이 도입 되었는데, var이라는 키워드로 사용할 수 있다.
var는 js나 C#의 var처럼, 변수를 선언할 때 타입을 var라고 적기만 하면 알아서 타입을 추론해서 초기화 해준다.
엄격한 타입이 강점인 자바에서 Var의 도입은 많은 반발이 있었지만, 편리한 경우도 꽤 있다.
아래와 같은 케이스를 확인해보자.
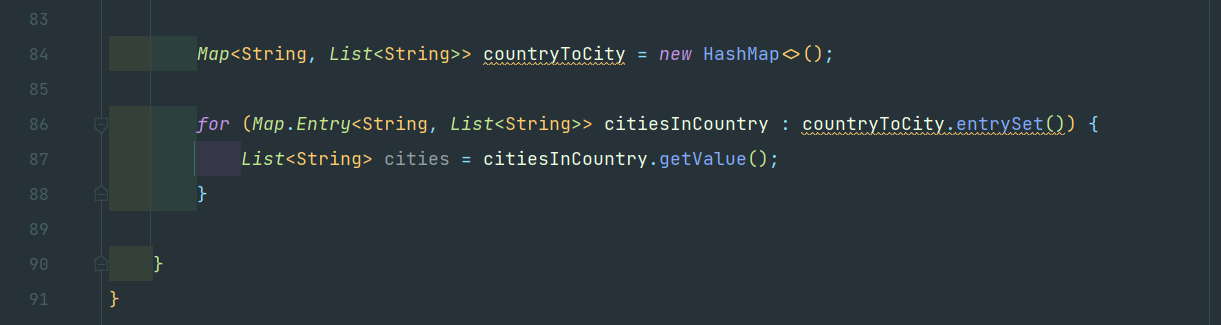
여러모로 복잡하다.
var를 사용한다면 아래와 같이 리팩터링 할 수 있다.

깔끔해졌다. 이 케이스는 가독성도 좋다.
또한 자바의 Non-Denotable한 요소에 대한 사용이 용이하다.
예를 들면 익명클래스는 그 타입을 마땅히 표현하기가 어렵다.
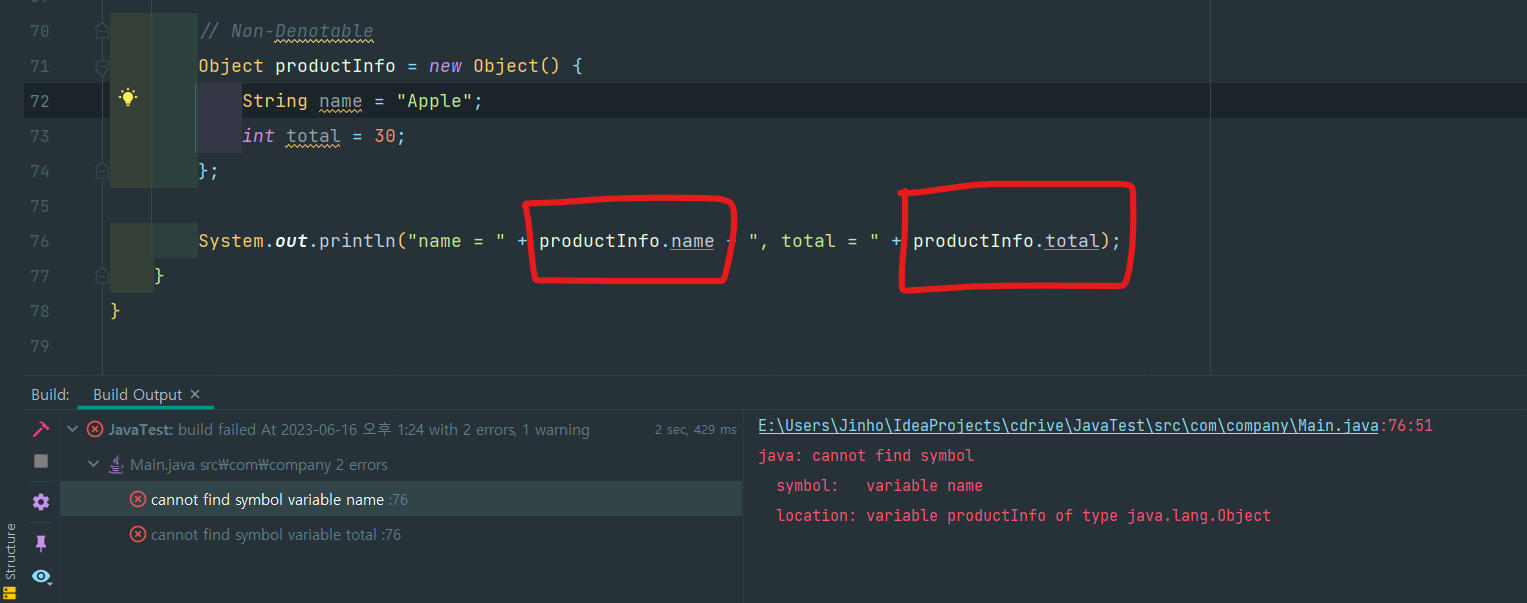
위와 같이 인텔리제이의 도움을 받아 익명 클래스를 변수로 받아 맴버를 호출해 보았다.
Object에는 저런 맴버가 없기 때문에 빨간 줄이 그어지며 컴파일에 실패했다.
하지만 VAR가 출동한다면?
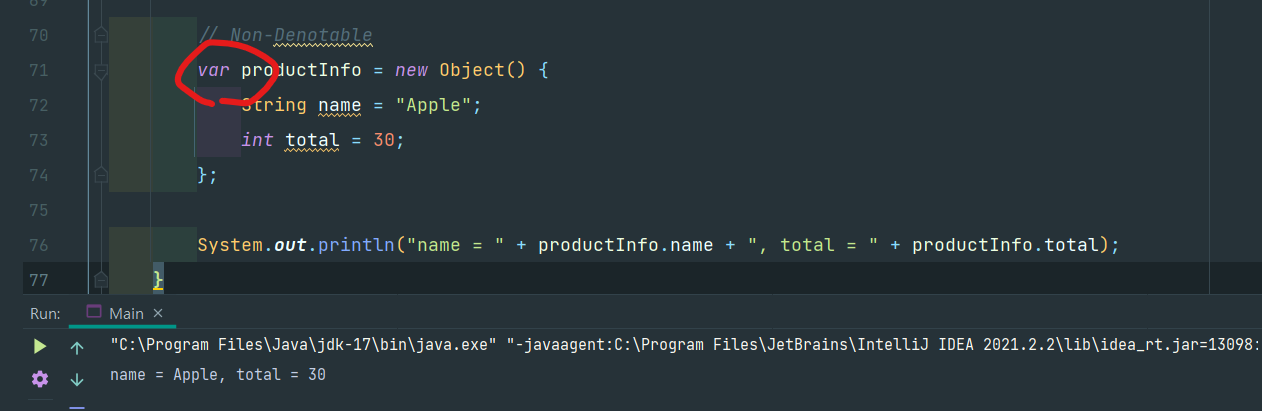
잘 호출됨을 확인할 수 있다.
5.1 var 사용시 유의할 점
var는 아래와 같은 세 경우에서 사용이 불가능하다
1. 매개변수로 사용할 수 없다.
2. 변수를 선언만 하는 경우 사용할 수 없다.
3. 람다와 함께 사용할 수 없다.
이 세 경우는 모두 추측할 거리가 없기 때문이다.
또한 고민해볼 점도 있다.
사용자 입장에선 물론 편리하겠지만, 읽는 사람 입장에선 자칫 잘못하면 가독성이 박살날 수 있다.
말 그대로 박살날 수가 있다.
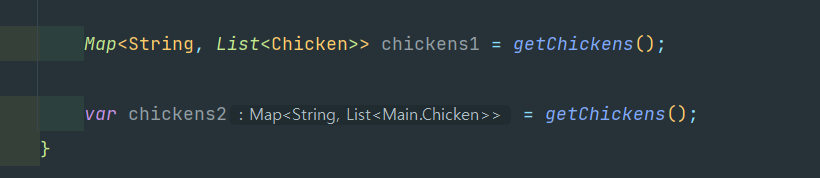
첫 번째 줄은 getChickens가 어떤 타입을 반환하는지 직관적으로 이해할 수 있다.
하지만 두 번째 줄은 어떨까? 직접 메서드를 확인해야만 추측할 수 있다.
참고한 아티클에 따르면 보통 현업 프로그래머는 코드를 짜는 시간 보다 읽는 시간이 10배 많다고 한다.
이런 상황에서 가독성이란건 협업을 위해 권장되는 사항을 넘어 필수 사항이라고 할 수 있다.
따라서, var를 쓸 때는 항상 가독성을 고려하며 사용해야 한다.
Reference
- 자바의 정석 <남궁성>
- [Eric! - String Constant Pool과 Constant Pool](https://deveric.tistory.com/123)
- [Chapter 2. The Structure of the Java Virtual Machine](https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html#jvms-2.6.2)
- [Chapter 4. Types, Values, and Variables](https://docs.oracle.com/javase/specs/jls/se7/html/jls-4.html#jls-4.3.1)
- [Chapter 10. Arrays](https://docs.oracle.com/javase/specs/jls/se7/html/jls-10.html#jls-10.8)
- [JVM 스택과 Frame](https://johngrib.github.io/wiki/jvm-stack/)
- [The Java™ Tutorials - Type Inference](https://docs.oracle.com/javase/tutorial/java/generics/genTypeInference.html)
- [Java 10 Local Variable Type Inference](https://developer.oracle.com/learn/technical-articles/jdk-10-local-variable-type-inference)
'🌱 Java & Spring 🌱' 카테고리의 다른 글
| 코드로 이해하는 Red-Black Tree의 연산과 Java TreeMap에서의 구현 (0) | 2024.04.09 |
|---|---|
| Java 인터페이스의 OOP적인 활용 (0) | 2023.07.20 |
| Lambda & Stream의 도입 배경과 원리, 최적화 전략! 알고 쓰자!!! (4) | 2023.06.02 |
| 바이트 코드를 JVM에 싸서 드셔보세요 (0) | 2023.05.24 |
| Bucket4J 사용하는 법 자세히 알랴드림 (0) | 2023.03.20 |