

람다와 스트림은 원리를 모른 채 사용되는 경우가 많다.
인텔리제이 자동완성, Chat GPT와 코파일럿의 도움을 받는다면, 사실 개념조차 몰라도 사용할 수 있다.
그런데 내가 그걸 왜? 알아야? 하지? 라고, 생각할 수도 있다.
몰라도 된다. 몰라도 코드를 작성하는 데 아무런 문제도 없고 Stream을 활용한 코드도 작성할 수 있다. (물론 주의할 점들은 있다)
하지만 왜 Java 진영에서 기존 패러다임인 객체지향에 다른 패러다임을 얹는 고생을 감수했고, 이 기술을 추가한데엔 다 이유가 있다. 람다와 스트림을 잘 알고, 잘 활용할 수록 당신은..
1. 큰 컬렉션을 "잘" 다룰 수 있다.
2. 더욱 유연하고 읽기 좋은 코드를 작성할 수 있다.
3. 상황에 따라 성능적인 이득을 볼 수 있다.
스트림의 수많은 기능의 "사용법"은 다양한 블로그 아티클과 도서 등에서 쉽고 자세하게 알려주고 있다. 대표적인 도서로는 "모던 자바 인 액션"에 잘 설명되어 있다.
구글과 각종 생성형 AI 덕분에 정보를 빠르고 간단하게 얻을 수 있게 되었다. 그래서 나는 구체적인 문법과 인터페이스 자체를 외우기 보다는 핵심 원리와 기술을 사용하는 목적을 파악하고, 사용법은 필요할 때마다 찾아보는 것을 선호하기 때문에 이 글에서는 최대한 사용법이 아닌 다른 것에 집중했다. 사람들이 관심을 적게 갖는 도입 배경과 람다와 스트림이 정확히 왜 좋고, 어떻게 동작하는지에 대해 적었다. 그리고 재미있는 스트림 최적화 전략과 병렬 스트림이 어떻게 동작하고 무엇을 조심해야 하는지 알아보자.
이제 Lambda & Stream이 정확히 무엇이고, 왜 쓰는 거고, 뭘 할 수 있으며, 어떻게 사용하면 좋을지 알아보자!
재미있는 이야기들이 있다.
1. Lambda Expression
1.1 람다의 도입 배경

진화란 무엇인가?
디지몬 어드벤처와 포켓몬스터가 아이들에게 많은 오해를 낳았지만,
생물은 특별한 방향을 두지 않고 "진화"한다. 더 나아지고, 더 나빠진다는 개념이 없다. 단지 생물들은 방향 없이 다양하게 변화하고 그것을 진화라고 부른다. 더 나아지고 나빠진다는 단지 환경에 따라 다르다. 지능이 나빠지는건 진화가 아닐까? 팔이 하나 사라지는건? 수북한 털이 모두 사라지는건? 모두 진화에 해당한다.
다만 선택은 환경이 하는 것이다. 끊임없이 변화하는 환경에 살아남기 좋은 방향으로 진화했다면 살아 남은거고, 아니면 죽어버리는 것이다. 이것이 "자연 선택설"이다.
자바 또한 다른 언어들보다 끊임없이 진화해왔다. 새로운 기능이 추가되고, 패러다임이 추가된다. 이것은 사람이 의도적으로 만들었기 때문에 어떤 의도가 담겨져 있겠지만, 결국 선택은 개발자들이 한다. 더 편한 언어가 있고, 더 나은 언어가 있으면 도태될 수 밖에 없다.
자바 또한 살아남기 위해서 끊임없이 진화해왔고, 지금도 계속해서 기능을 붙여 나가고 있다.
이유는 빠르게 변화하는 환경에서 살아남기 위해서이다.

많은 언어가 생기고, 또 사라졌다. 총 700개가 넘는 프로그래밍 언어 중 우리는 몇 개나 그 존재를 알고 있나?
사용자들의 니즈에 맞지 않는 언어는 자연스럽게 죽게된다. 자연에게 선택받지 못하는 것이다.
우리의 환경은 어떻게 변했는가?
각종 웹-앱 서비스의 사용이 폭발적으로 증가했다. AI와 빅 데이터 세상이 오면서, 큰 데이터를 잘 다루는 것이 매우 중요해졌다. 그리고 하드웨어도 발전했다. 멀티 코어 프로세서의 발전으로 잘 활용한다면 거대한 작업을 나누어 수행할 수 있게 되었다.
자바 컬렉션은 이미 강력했다. 하지만, 테라바이트 급 혹은 거의 무한한 크기의 데이터 셋을 다루기엔 불편한 점이 많았다.
웹 애플리케이션 세상에서 큰 위치를 차지하고 있던 자바에게도 데이터들을 더욱 잘 다루기 위한 변화가 필요해졌다. 자연의 선택을 받기 위해서..
이전의 자바는 하나의 코어만을 사용했고, 나머지 코어를 사용하기는 쉽지 않았다.
멀티 코어 컴퓨터들이 넘쳐나는 세상이 왔는데도 말이다!
이러한 맥락에서 병렬성의 활용과 간결한 코드를 위해, 자바 8 이후 아래 기술들이 도입되고 강화되었다.
1. 메서드의 1급 시민화
2. 스트림 API
3. 인터페이스의 디폴트 메서드
디폴트 메서드를 활용해 컬렉션을 강화하였고, 거대한 컬렉션을 분산 환경에서 다루기 위한 병렬화 기술이 강화 되었다.
그리고 이 컬렉션을 좀 더 효율적으로 다루기 위해 스트림이 강화되었고,
스트림을 편리하게 사용하기 위해 선언형-함수형 프로그래밍이 도입되었다.
그리고 선언형-함수형 프로그래밍을 위해 람다가 도입되었다.
결국 컬렉션을 효율적으로, 편리하게 "잘" 다루는 것이 최종 Goal이다.

데이터셋을 보다 복잡하게 다루는 상황이 많아지면서, 기존의 자바에서 사용하던 방식은 꽤나 불편하게 느껴졌다.
for문을 이용해 순회하며, 내부적으로 if문을 사용하고, 또 그 안에서 for문을 사용하고, 분기하고..
우리는 "무엇을" 하려는지 보다는 "어떻게" 하는지에 집중할 수 밖에 없었다.
이런 불편함을 해결하고 싶고, 스트림을 보다 편리하게 사용하기 위해 도입된 것이 선언형-함수형 프로그래밍이다.
스트림을 사용한다면 이 자료구조로 "무엇을"할지만 이야기하고, "어떻게"할지에 대한 이야기는 따로 생각할 수 있다.
이런 SQL과 같은 선언형적인 프로그래밍을 위해 람다가 도입 되었고,
람다를 위해 함수형 인터페이스가 도입되었다. (메서드를 일급 값으로 사용하는 것은 함수형 프로그래밍의 아이디어다)
람다의 도입으로 자바는 더 이상 예전의 자바가 아니게 되었다.
자바는 람다식의 도입으로 인해, 객체지향언어인 동시에 선언형-함수형 언어가 되었다.
새로운 패러다임이 추가된 것이다!
극단적으로 생각하면 객체지향 프로그래밍과 함수형 프로그래밍은 상극이다.
어떻게 자바는 기존의 객체지향 세상을 무너뜨리지 않으면서 함수형 프로그래밍을 도입할 수 있었을까?
이제 람다와 함수형 인터페이스 부터 스트림까지 이어지는 이야기를 해보겠다.
1.2 람?다
람다"식"은 메서드를 하나의 "식"으로 표현한 것이다.
그리고 람다란 코드 블록이다.
일단, 람다식의 예시를 살펴보자.
람다식을 적용하면 메서드의 이름과 반환값이 없어진다.
그래서 람다를 이름이 없다는 의미로 익명함수라고도 부르는 것이다.
마치 익명 객체를 익명 객체라고 부르는 것과 비슷한데 용도도 비슷하다. 다양한 예시를 만나면서 어떻게 쓸 수 있는지 확인해보자.
1.2.1 람다와 메서드를 람다로 바꾸는 예시들
람다는 아래와 같은 구조를 갖는다.
(매개변수_목록) -> { 로직 }
앞서 말한대로 우리가 알고 있는 메서드의 정의와는 조금 다르다.
어떻게 다른가?
1. 메서드 이름이 없다.
2. 반환 타입이 없다.
다른 예시를 보이겠다. 일반 메서드를 람다로 표현해보자.
void foo() {
System.out.println("lambdadi lambdadi lambdadida");
}위와 같은 메서드를 아래와 같이 나타낼 수 있다.
() -> {
System.out.println("lambdadi lambdadi lambdadida");
};
이름 "foo"와 반환 타입 "void"를 제거했다.
그리고 매개변수 리스트를 괄호 안에 표현했는데, foo()는 매개변수가 없으니 ()로 나타냈고, 매개변수 리스트와 메서드 바디는 -> 화살표로 이었다.
로직이 한 줄인 경우 중괄호도 없앨 수가 있다.
() -> System.out.println("lambdadi lambdadi lambdadida");
깔끔하지만, 뭘 하려는지는 알 수 있지 않는가?
"저 String을 출력하겠구나"라고 쉽게 알 수 있다.
다른 예시도 보자.
만약 리턴값이 있는 메서드였다면, 중괄호를 지우면서 'return'을 지울 수 있다.
또한 타입이 확실하다면 매개변수의 타입을 지울 수 있다.
int max(int a, int b) {
return a > b ? a : b;
}
위와 같은 메서드를 아래와 같이 나타낼 수가 있다.
분명 return 타입을 명시하지 않았다! 하지만 Java의 Type Inference로 추론이 가능하다.
a와 b는 int임이 자명하니, 반환도 int겠구나..
(int a, int b) -> {
return a > b ? a : b;
}
그리고 중괄호를 없애며 아래와 같이 return을 지울 수 있다.
(int a, int b) -> a > b ? a: b
깔끔하다. 그러면서도 뭘 하려는지도 쉽게 알 수있다.
잘 보면 문장 가장 뒤에 세미콜론이 없다. 중괄호까지 없애는 경우엔 세미콜론을 붙이지 않는다.
이는 람다 표현"식"이기 때문이다.
여기서 또 있다.
매개변수 타입이 추론 가능하다면, 아래와 같이 매개변수 타입도 생략도 가능하다.
(a, b) -> a > b ? a: n
타입을 명시해야 코드가 더 명확한 경우나, 컴파일러가 타입을 판단할 수 없는 경우가 아니라면, 람다의 모든 매개변수 타입은 생략하는 것이 좋다. 특히 매개변수 이름이 매우 긴 경우에 유용하다.
더 자세한 내용은 이펙티브 자바 Item 42를 참고하자 간단하게 정리해둔 글의 링크를 첨부한다.
매개변수가 하나라면 아래와 같이 표현할 수도 있다.
(a) -> a * a
a -> a * a
괄호를 없앤 것이다.
스트림에선 이런 표현을 자주 쓰게 될 것이다.

이름 하나 하나를 확인하며 어떤 수행을 하는 코드이다. 이때 중간의 람다식을 보면 "name"에 괄호가 없다는 사실을 알 수 있다.
람다를 적극적으로 활용하면 메서드를 다양한 방식으로 좀 더 간결하게 나타낼 수 있다.
우리가 평소 사용하는 메서드들을 정의하기 위해 이런 람다를 사용하는 것은 아니다.
익명 객체와 똑같다. 위 사진과 같이 한번 쓰고 버릴 메서드가 있다면, 람다로 간단하게 정의해 사용할 수 있다.
람다가 없었을 때는, 위와 같이 name.startWith를 호출하는 어떤 메서드를 정의하고, 필요한 경우 그 메서드를 가진 객체를 정의해서 사용해야 했을 것이다.
이러한 람다식의 다양한
배리에이션을 아는건 편리함을 주고 가독성을 높힐 수 있게 돕지만, 외우는게 중요하지는 않다.
어차피 필요할 때 구글링 하거나, 인텔리제이에서 알아서 도와줄 것이기 때문이다.
이런게 가능하다 정도를 알면 좋을 것이다. 쓰다 보면 손에 익을 것이다.
1.2.2 람다로 복잡한 Enum 리팩토링
이제 람다를 활용해 복잡한 Enum을 리팩토링 하는 케이스를 살펴보자.
아래와 같은 복잡한 상황도 람다와 함께 리팩토링 하면 간결해진다.

Enum 상수마다 조금은 다른 동작을 보여야 하는 apply라는 메서드가 있다고 해보자. Operation clss는 상수에 따라 다른 계산 방식을 보여야 한다. 이를 아래와 같이 간결하게 리팩토링 할 수 있다.

너무 깔끔하다!
1.2.3 이제 클래스에 속해있지 않아도 돼!!!
기존 자바의 모든 정의는 클래스 안에서 이루어질 수 있었다.
이 엄격함은 사람들이 C++보다 자바를 더 좋아하는 이유 중 하나였으나,
메서드는 어딘가 클래스에 포함되어야 하기 때문에, 여러 귀찮은 제약들이 많았다.
정의하기 위해 클래스를 만들어야 했고,
static이 아닌 경우 호출을 위해 객체도 만들어야 했다.
이런 귀찮음을 해결해 주는 것이 바로 람다식이다.
람다식과 메서드 레퍼런스로 메서드는 이제 주고 받을 수 있는 값인 1급 값이 되었다.
람다식은 매개변수로 전달 되는 것도 가능하고, 결과로 반환될 수도 있다.
이로인해 마치, 메서드를 변수처럼 다루는 것이 가능해진 것이다.
이미 자바 버전이 많이 올라간 상태에서 처음 배운 사람들이나,
js를 먼저 배운 사람이라면 이런 사용이 좀 더 자연스럽게 느껴질 수도 있을 것이다.
어쨋든!
1급 값이란 무엇이고, 주고 받는 것의 장점은 대체 무엇일까?
1.3 일급 값과 동작의 파라미터화

자바 8의 가장 큰 변화중 하나는 "동작의 파라미터화"이다.
말이 복잡한데 하나 하나 뜯어 봅시다
어떤 코드로 나타내어진, 주로 메서드로 표현되는 "동작"을
메서드의 "파라미터"로 사용할 수 있다는 것이다.
앞서 람다식에서 본 것과 같이 우리는 이제 메서드를 마치 변수처럼 주고 받을 수 있게 되었다.
기존의 자바를 생각해보자. 우리가 주고 받을 수 있는 값은 primitive 값과, 객체의 인스턴스의 주소! 래퍼런스 값을 주고 받을 수 있었다. 변수에 할당하거나, 메서드의 파라미터로 설정해 주고 받거나, 반환값으로써 사용할 수 있었다.
이런 값들을 "1급 값"이라고 부른다. 다른 표현으론 "1급 시민"이라는 표현이 있다.
미국에서 자유롭게 거주하고, 출입국의 자유를 갖는 시민을 1급 시민이라고 한다.
기존 자바 세상에서, 이런 1급 대우를 받지 못하는 클래스와 메서드는 이급 시민이였다.
클래스의 인스턴스를 주고 받는 것 말고, 클래스 그 자체를 주고 받는 방법은 없었다.
람다는 메서드를 1급 시민으로 만들면서, "동작"을 "파라미터화"시켰다.
덕분에 엄청난 편리함이 따라오게 되었는데, 전략패턴과 비슷한 템플릿 콜백 패턴에 이를 활용할 수 있다.
1.3.1 템플릿 콜백 패턴과 람다
전략 패턴은 같은 하나의 메서드에서, 사용하는 인터페이스의 구현체에 따라 다른 알고리즘을 적용하고 싶을 때 사용할 수 있는 전략이다.
예를 들어 "무기"라는 인터페이스가 있고 "공격"이라는 메서드를 가지고 있다고 해보자.
아래와 같이 구현하면 군인은 "무기"의 구현체에 따라 실제론 다른 알고리즘을 사용할 수 있다.

"무기" 인터페이스의 구현체의 인스턴스를 인수로 받아왔으니,
군인이 공격할 때마다 무기 인터페이스 구현체가 구현한 "공격" 메서드를 실행 가능하다.
두 가지 예시를 보겠다. 처음엔
아래에 "무기" 인터페이스의 구현체 클래스 "총"과 "돈까스 망치"를 넣어주겠다.
둘의 "공격"은 각자 다른 소리를 내며 공격한다.
(각각 "빵야"와 "와장창")
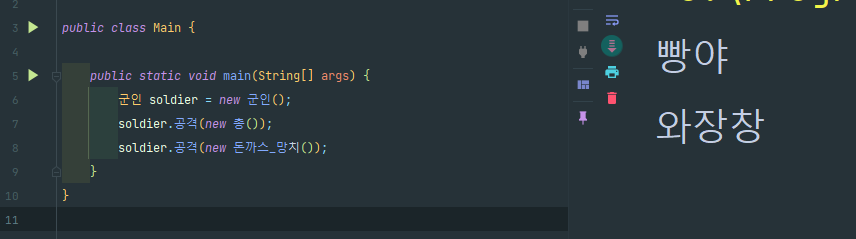
이러한 전략 패턴을 활용하면 우리는 "총을 든 군인", "돈까스 망치를 든 군인" 클래스를 따로 구현할 필요가 없어진다!
이러한 구현을 람다를 활용해 똑같이 구현해볼 수 있다.
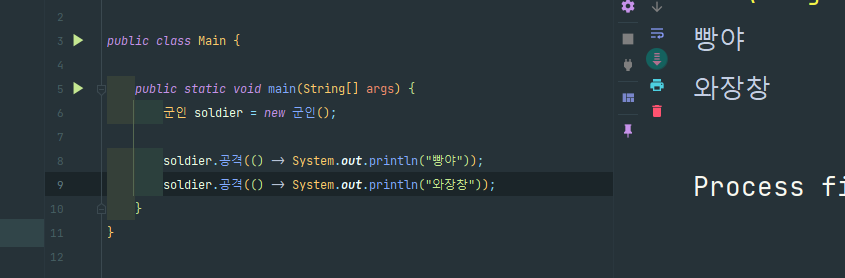
이건 템플릿 콜백 패턴인데, 이런 식으로 메서드 자체를 전달할 수가 있게 된 것이다!!
람다를 활용했더니, 이제 "무기" 인터페이스를 상속한 "총", "돈까스 망치" 클래스를 만들 필요 조차도 없어지게된 것이다.
정말 편리하고 신기하다!!
(인터페이스와 OOP에 더 알아보고 싶다면 제가 쓴 글을 봐주세요)
1.4 람다식의 정체는 메서드인가?
람다식은 내부적으로 어떻게 작동하는 것일까?
생각해보면 이상한 일이다.
기존의 객체지향적 패러다임을 가진 자바의 세계에선 아예 불가능했던 메서드의 전달을 가능하게 해줬다.
하지만 기존의 탄탄한 자바 세계에 큰 영향을 미치지 않으면서도 다른 프로그래밍 방식을 제공한다는게 과연 쉬웠을까?
정말 수 많은 고민이 있었을 것이다.
람다식을 일종의 메서드라고 위에서 언급했다.
그래서 람다식의 정체는 무엇인가? 정말 메서드일까?
람다식의 실체는 메서드가 아닌, 익명 클래스의 객체이다.
객체라고?
(int a, int b) -> a > b ? a : b;
위와 같은 람다식은 실제로는 아래와 같이 생겼다고 이해하면 된다.
new Objcet() {
int max(int a, int b) {
return a > b ? a : b;
}
}
익명 클래스의 인스턴스를 만든다.
그리고 내부적으론 메서드를 가지게 한다.
람다식은 위와 같은 익명 클래스의 인스턴스이다.
(max는 예시를 위한 이름)
왜 람다를 익명 클래스의 객체로 표현했을까?
이에 대해 이해하려면 우선 함수형 인터페이스를 이해해야 한다.
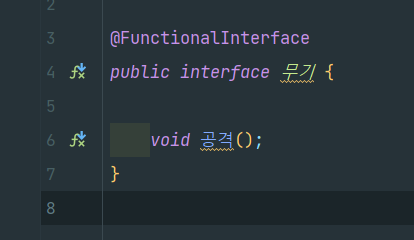
1.5 함수형 인터페이스란 무엇인가?
추상 메서드를 하나만 갖는 인터페이스를 함수형 인터페이스라고 한다.

위는 함수형 인터페이스의 예시인 Runnable이다.
어떻게 구성되어 있는지 살펴보자.
`@FunctionalInterface`라는 어노테이션 하나와 추상 메서드 하나가 덜렁있다.
이게 무슨 의미가 있나..? 하겠지만,
앞서 람다식은 식을 변수와 같이 다룰 수 있게 해주며
익명 객체의 인스턴스라고 표현했다는 점을 기억하자
즉, 함수형 인터페이스가 가지고 있는 public 메서드를 람다식으로 묘사하면, (위 그림에서는 run())
내부적으로 익명 객체가 만들어 지면서, 해당 식을 전달할 수 있도록 감싸준다.
이러한 방식으로 람다식을 함수형 인터페이스의 구현체 인스턴스로 생각하고 아래와 같이 변수처럼 사용할 수 있다.
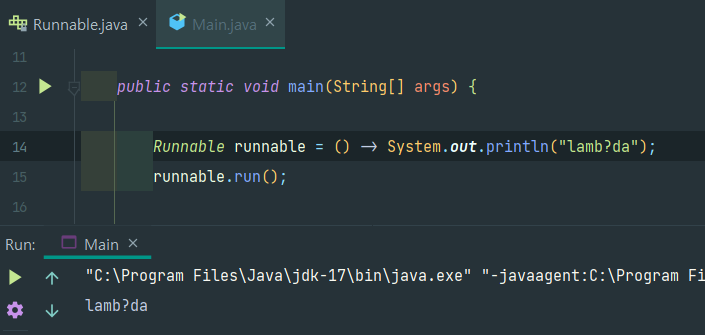
void 반환 람다식인 `() -> System.out.println("lamb?da")` 를
void 반환 추상 메서드를 가진 함수형 인터페이스 Runnable형 참조 변수로 받고 있다.
그리고 run()을 호출하니, 람다식이 실행된 것을 확인할 수 있었다!!
위 람다식은 사실 아래와 같이 구성되어 있을 것이다.
new Objcet() {
public void run() {
// 문장 출력;
}
}
함수형 인터페이스는 이렇게 활용할 수 있다.
자바가 미리 만들어 놓은 함수형 인터페이스들을 예시들을 보며 함수형 인터페이스에 대해 더 알아보자
1.5.1 자바가 제공하는 함수형 인터페이스의 예시들
아래는 java.util.function 패키지 안에 있는 함수형 인터페이스들이다.
절대 외우라고 적은 것은 아니므로 안심하자. 뭐가 있는지 정도만 알면 활용할 때 찾아도 문제 없다.
| 인터페이스 이름 | 가지고 있는 메서드 |
| Runnable | void run() |
| Supplier | T get() |
| Consumer | void accept(T t) |
| Function<T, R> | R apply(T t) |
| Predicate | Boolean test(T t) |
| UnaryOperator | T apply(T t) |
Runnable run = () -> System.out.println("hello");
Supplier<Integer> sup = () -> 3*3;
Consumer<Integer> con = num -> System.out.println(num);
Function<Integer, String> fun = num -> "input: " + num;
Predicate<Integer> pre = num -> num > 10;
UnaryOperator<Integer> uOp = num -> num*num;
자바 8 API에서는 여러가지 용도로 이용할 수 있는 함수형 인터페이스들을 제공한다.
각 이름에 맞는 용도를 가지고 있고, 적절하게 사용하면 좋을 것 같다.
이름을 통해 그 용도를 충분히 추측할 수 있다.
예를 들어 입력이 없고, 반환값이 없는 메서드를 실행 "Run"한다고 표현하겠다 -> "Runnable"
입력은 없지만 반환값이 있는 경우 "Supply" 한다고 표현하겠다 -> "Supplier"
입력을 받지만, 반환값이 없는 경우 "Consum"한다고 표현하겠다 -> "Consumer"
이외에도 똑같이 생각하면 된다.
무려 43가지 함수형 인터페이스를 제공한다고 하니
외울 필요는 없어 보이지만, 한번 슥 보면 좋을 것이다.
람다는 이런 식으로 만들어졌다.
하나의 메서드가 선언된 인터페이스를 정의해서 람다식을 다루는 것은 기존의 자바의 규칙들을 어기지 않으면서도 자연스럽다.
이렇게 자바는 기존의 세계에 최대한 적은 영향을 주면서 람다식을 구현해냈다.
이제 함수를 구현할 때, 람다를 염두에 두면 더욱 유연하고 좋은 메서드를 구현할 수 있을 것이다.
1.6 직접 함수형 인터페이스를 선언해보자!
이번엔 직접 함수형 인터페이스를 선언해보면서, 더욱 자세히 이해해보자.
인터페이스에 단 하나의 추상 메서드만을 갖도록 만들면 된다. 인터페이스 위에 @FunctionalInterface를 붙이면, 올바르게 함수형 인터페이스를 정의하였는지 체크해준다. 즉, public 메서드가 1개 초과인 경우 컴파일 에러를 발생시킨다.
@FunctionalInterface
public interface TestFunctionalInterface {
public abstract int max(int a, int b);
}람다식은 익명 클래스의 객체이므로, 아래 두 표현은 같은 표현이다.
MyFunctionalInterface test = new MyFunctionalInterface() {
@Override
public int max(int a, int b) {
return a > b ? a : b;
}
};
MyFunctionalInterface test1 = (int a, int b) -> a > b ? a : b;이렇게 직접 함수형 인터페이스를 만들 수 있지만, 이펙티브 자바 Item 44에서는 아주 많은 함수형 인터페이스를 제공하기 때문에 이미 만들어 진 것이 있다면 찾아서 사용할 것을 권한다. 이들은 여러 디폴트 메서드를 제공하여 높은 상호운용성을 제공하고, 읽는 사람도 배워야 할 개념이 줄어든다. (predicate는 predicate를 조합하는 디폴트 메서드를 제공한다)
1.7 함수형 인터페이스 타입의 매개변수와 반환 타입
람다식은 참조변수로써 다룰 수 있다.
앞에서 부터 계속 언급햇던 내용이다.
이제 부터 중요하다.
만약 메서드의 반환 타입이 함수형 인터페이스라면,
함수형 인터페이스의 추상형 메서드와 동등한 람다식을 가리키는 참조변수를 반환하거나,
람다식을 집접 반환할 수 있다.
혹시 앞서 전략패턴을 설명할 때 보였던 군인과 무기의 예시가 기억나는가?
바로 "무기" 인터페이스가 함수형 인터페이스였던 것이다! (두둥)
입력과 반환이 void인 공격 메서드를 정의해줬다.
덕분에 아래와 같이 파라미터와 반환이 없는 람다식을 전달해 줄 수 있었다!
사실 람다식의 본질은 객체이기 때문에,
사실은 객체를 주고 받는 것이라서 옛날의 객체지향 시절의 구현과 근본적으로 달라진 것은 하나도 없다!
하지만, 얼마나 간결하고 이해하기 쉬운가!
이렇게 만들기 위해 자바 진영이 엄청난 고민을 했을 것이다.
@FunctionalInterface
public interface TestFunctionalInterface {
void goGoSing();
}
아래와 같이 반환시켜 버릴 수 잇다.
// TestFunctionalInterface 참조 변수로 받으면, 람다함수 참조 변수가 된다.
static TestFunctionalInterface getFuction() {
return () -> System.out.println("Run~");
}
아래의 execute는 직접 만든 TestFunctionalInterface를 매개변수로 정의 해주었다.
static void execute(TestFunctionalInterface test) {
test.run();
}
public static void main(String[] args) {
execute(() -> System.out.println("오마 오마 갓~"));
// 함수형 인터페이스 참조 변수로 받을 수도 있다.
TestFunctionalInterface test = () -> System.out.println("예상 했어 난~");
test.goGoSing();
}
그 다음, execute의 인자로 람다식을 넣어 주었다.
또 위에서 한번 다뤘지만, 참조 변수에 할당해 호출도 해 보았다.

잘 나온다 잘 나와
1.8 람다식의 타입은 함수형 인터페이스 타입이 아니다?
바로 위에서 함수형 인터페이스의 참조변수로 람다식을 참조할 수가 있었다.
그렇다면, 람다식의 타입이 함수형 인터페이스의 타입과 일치하는가?
당연한거 아니여? 일치 해니께 받아진거 아녀?
TestFunctionalInterface test = () -> System.out.println("무야호~");
위와 같이 할당 가능하니, 오른쪽 람다식의 타입은 TestFunctionalInterface일까?
람다식의 타입?
아까는 람다식은 익명 객체라며, 익명 객체는 타입이 없어야 하는거 아닌가?
정확히 말하자면, 위와 같은 람다식은
타입은 있지만 컴파일러가 임의로 이름을 정하기 때문에 알 수가 없다.
그래서 사실은 묵시적으로 (TestFunctionalInterface)가 붙어 형변환이 이루어 지는 것이다.
// 특이하게도 Object로의 형변환은 안 된다. 함수형 인터페이스로의 형변환이 허락되고,
// 굳이 Objcet 만들려면 함수형 인터페이스로 바꾼 다음 Object로 바꿔주면 또 된다.
그래서 대체 무슨 타입이라고...;
컴파일러는 람다식의 타입을 외부클래스의 이름을 이용해서 만든다.
마치 익명 객체의 타입을 만들 때와 같다.
일반적인 익명 객체는 익명 객체가 만들어진 외부 클래스의 이름과 조합되어
외부클래스$번호와 같은 타입을 갖는데,
람다식의 경우 외부클래스이름$$Lambda$번호와 같은 형식을 갖는다.
실제로 그런지 살펴보자
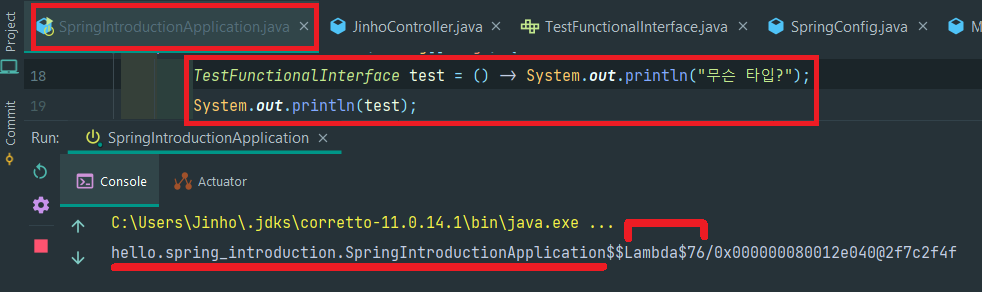
외부 클래스의 이름인 SpringIntroductionApplication에 $$이 붙었고
Lambda라는 글씨 다음에 $이 붙었다.
그리고 76이라는 숫자가 붙었다. 76은 컴파일러에 의해 자동으로 붙는 숫자로
외부 클래스 안에서 람다식을 식별하기 위해 붙는다. (JVM 구현 마다 다름)
1.9 왜 익명 클래스가 쓰인 것일까?
왜 이렇게 익명 객체에 넣어서 전달하는걸까?
이는 옛날 부터 JDK 1.1 이후 함수를 간접적으로 전달할 떄 익명 함수를 활용했기 때문이다.
분명 함수를 "바로" 전달할 수 있는 방법은 없었다.
다만 익명 함수를 통해 간접적으로 전달할 수 있었다.

위의 코드는 names라는 리스트의 객체들을 길이순으로 정렬하는 코드이다.

sort는 두 번째 인자로써 Funtional Interface "Comparator"를 전달해주면 되는데, compare 라는 같은 타입의 객체 2개를 받아 int를 반환한다. 지금이야 저런 람다식 표현이 가능했지만, 예전엔 아래와 같이 익명 객체로 전달해 주어야 했다.

앞서 언급한 템플릿 콜백 패턴의 원형이 바로 익명 객체를 전달하는 방식이였다.
하지만, 이제는 람다가 있다!
익명 클래스 방식은 코드가 너무 길고 복잡하다.
람다는 가독성도 좋고 간결하기 떄문에, 스트림과 더욱 잘 어울린다.
이펙티브 자바 아이템 42에선, 보통의 상황에선 익명 클래스 보다 람다를 사용하라고 권한다.
단, 함수형 인터페이스가 아닌 타입의 인스턴스를 만들어야 하는 경우엔 사용해도 좋다고 한다.
1.10 외부 변수를 참조하는 람다식
람다식은 익명 객체이므로, 참조하는 클래스의 지역변수를 final로 만든다.
즉, 상수로 간주되게 만든다.
method라는 메서드는 height라는 변수를 가지고 있다.
그리고 람다식에서 height를 참조하는 부분은 주석 처리 되어 있다.
키가 187이였으면 좋겠다는 나의 소망을 담아 187로 재할당 해주었다.
아무런 오류도 없다.

람다식에서 height를 참조하는 부분의 주석을 해제해 주었다.

바로 경고가 뜬다
람다 표현식 내부에서 사용되는 변수는 final이여야 한다는 것이다...
키 187의 꿈은 이룰 수 없나 보다..
재할당 하는 부분을 없애면 또 뭐라고 안 한다.

정말 너무하다.
그리고 소소하지만, 한 스코프로 취급되어
메서드에서 사용중인 변수와 같은 이름의 매개변수 선언이 불가능하다.

1.11 Method Reference
앞서 한번씩 언급했던 메서드 참조에 대해 이야기 해보자.
메서드 참조를 이용하면 기존의 메서드 정의를 재활용해 람다와 같이 사용할 수 있다.
그리고, 가독성에 장점이 있다. 일종의 람다 표현식의 축약형이라고 생각할 수 있다.
"어떻게" 메서드를 호출하는지 숨기고 "이 메서드를 호출하라"와 같이 선언형에 더 걸맞는 축약형인 것이다.
그래서 변환이 가능한 경우, 인텔리제이는 메서드 래퍼런스로의 변환을 노란 밑줄과 함께 추천한다.
람다식이 하나의 메서드만을 호출하는 경우,
메서드 레퍼런스의 형식으로 바꿀 수 있다. 메서드 레퍼런스에는 3가지 유형이 있다.
- 정적 메서드 참조 : 클래스::정적메서드
- 인스턴스 메서드 참조 : 클래스::인스턴스메서드
- 기존 객체의 인스턴스 메서드 참조 : 인스턴스::인스턴스메서드
예시를 보면 좀 더 명확한데, 아래와 같은 이쁜 표현이 가능하다.

잘 보면, map안의 Math.sqrt()를 사용하는 부분은 클래스::정적메서드형식으로 바뀌었고,
forEach를 쓰는 부분도 인스턴스::인스턴스메서드형식으로 바뀌었다.
입력으로 들어가게 될 인자를 특정해주지 않았는데, 어떻게 가능할까?
어차피 위 상황에서 쓰이는 인수는 오해의 소지 없이 명확하기 때문이다.
map의 결과는 어차피 컬렉션의 원소들을 하나 하나 꺼내어 보는 형태일테니,
squt에 인수로 그 원소 하나 하나가 들어간다는 이해가 가능하고,
forEach 또한 내부 원소를 하나 하나 순회하므로 동일하다.
마지막으로 클래스::인스턴스메서드형태도 살펴보자.
BiFunction<Integer, Integer, Integer> bip = (a, b) -> a.compareTo(b);
BiFunction<Integer, Integer, Integer> bip = Integer::compareTo;
다양한 형태로 메서드 래퍼런스 표현이 가능하다.
이펙티브 자바 Item 43에선 람다 보다는 메서드 참조를 사용할 것을 권한다.
더욱 간결한 표현이 가능하기 때문이다. 따라서 메서드 참조를 적용할 수 있고, 더 짧고 명확하다면 메서드 참조를 사용하라.
1.12 생성자도 Method Reference로 표현 할 수 있다
생성자를 호출하는 람다식도 메서드 참조로 변환할 수 있다. WOW
Supplier<TestClass> factory = () -> new TestClass();
Supplier<TestClass> factory = TestClass::new;
// 매개 변수 여러개인 경우
Function<Integer, TestClass> factory1 = (elem) -> new TestClass(elem);
Function<Integer, TestClass> factory1 = TestClass::new;
BiFunction<Integer, String, TestClass> factory2 = (elem, elem2) -> new TestClass(elem, elem2);
BiFunction<Integer, String, TestClass> factory2 = TestClass::new;
// 배열
Function<Integer, int[]> factory3 = (x) -> new int[x];
Function<Integer, int[]> factory3 = int[]::new;매개 변수가 있는 생성자라면, 그에 맞는걸로 해주면 된다. 물론 배열도 된다.
2. 스트림 (stream)
먼 길을 돌고 돌아 이제 스트림 이야기다.
스트림이란 앞서 언급한 것 처럼!
빅 데이터의 중요성이 증대되면서, 병렬화 기술을 이용한 컬렉션 사용의 효율을 높이기 위해 등장했다.
기존의 for 문이나, Iterator을 이용한 탐색은 길고 알아보기도 힘들었고,
재사용성도 떨어졌으며,
소스별로 다루는 방식이 달라 여간 불편한 것이 아니였다.
소스별로 다루는 방식이 다르다는건, 배열이냐, ArrayList냐 등
해당 컬렉션이 어떤 방식으로 구성되었느냐에 따라 다루는 방식이 달랐다는 의미이다.
뭐가 불편해요? Iterator 있잖아요?
컬렉션을 위한 인터페이스 Iterator가 물론 있지만,
컬렉션 클래스는 중복 정의 메서드가 너무 많았다..
예를 들어 List는 Collections.sort()로 정렬하고,
배열은 Arrays.sort()로 정렬하고.. (복잡~) 더 편리한 새로운 추상화가 필요했다!
그래서 나온 것이 자바 스트림 API 이다. 데이터 소스들을 아름답게 추상화 하였고, 이를 통해 재사용성이 높아졌다.

스트림이란 한번에 한개씩 만들어지는 연속적인 데이터 항목들의 모임이다.
프로그램들은 입력 스트림을 통해 데이터를 하나씩 읽고, 출력 스트림을 통해 한개씩 기록한다.
자바 스트림 API 또한 비슷하다.
마치 조립라인처럼 어떤 항목에 원하는 처리를 파이프라인처럼 연속적으로 이어주며 처리할 수 있게 해준다.

어떤 목적의 로직인지 한번 추측해보자.
다행이도 변수명이 힌트가 되긴 하지만, 꽤나 귀찮다.
일단 String List인 top3LowColorieDishNames
dishes라는 Dish의 리스트를 순회하는데.. 칼로리가 300 이상인 경우엔 넘어가고, 미만인 경우에만 리스트에 Dish의 이름을 저장한다... 그리고, 3개가 모이면 순회를 그만둔다...
직관적으로 파악할 수 있는 것은 아니다. 그리고 "무엇을"이 아닌 "어떻게"에 집중되어있다.
이 말이 와닿지 않을 수 있는데, 스트림으로 개선한 코드를 보면 이해될 것이다.

dishes 리스트에서 스트림을 생성한다.
그리고 dish의 칼로리가 300 미만인 dish를 "필터링"하고 (남기고)
Dish의 메서드 getName을 호출한 다음에,
3개의 원소를 List에 collect 하여 저장한다.
이것이 "무엇을"이 강조된 코드이다.
각 단계별로 어떤 "무엇을" 수행할 것인지 명시했기 때문에, 이해하기가 쉽다.
사용된 메서드 filter, map, limit, collect의 내부 구현을 자세히 읽을 필요도 없이, 이름만으로 의도를 파악할 수 있었다.
이것은 마치 SQL과 같다.
SELET * FROM members m WHERE m.name = '진호우'
그저 선언하는 것이다. "members 테이블에서, 이름이 '진호우'인 사람의 모든 컬럼을 가져와 줘"
이러한 특성 때문에 스트림은 선언형 프로그래밍의 성격을 가졌다고 표현한다.

메서드 이름만 적절하게 지어 놓는다면,
몇 줄만 보고도 뭘 하는지 금방 이해할 수 있다.
또 하나의 예시를 보자

위의 코드는 배열을 정렬하고, 짝수만 출력하는 코드다.
위와 같은 코드를 스트림을 통해 깔끔하고 직관적으로 나타낼 수 있다.

이 밖에도 통계를 낸다던지, 그룹을 지을 때도 편리하다.
스트림은 아주 다양한 기능을 제공한다.
대충 맛을 봤으니, 이제 스트림의 대표 성질들에 대해 알아보자.
2.1 스트림의 기본 특징
1. 스트림은 데이터 소스를 변경하지 않는다.
스트림은, 데이터 소스로 부터 데이터를 읽어오기만 한다.
그 소스를 변경하지 않는다.
2 스트림은 일회용이다.
스트림은 Iterator와 같이 일회용이다. 스트림을 한번 사용하고 나면, 재사용이 불가능하다.
stream1.sorted().forEach(System.out::println);
int size = stream1.count(); -> 불가능!
1과 결합되어, 원본 소스를 변경하지 않고
새로운 스트림만 만들어 내어 일회용으로 사용하고 버린다.
3 스트림은 작업을 내부 반복으로 처리한다!
스트림이 간결할 수 있었던 비결 중의 하나가 내부 반복이다.
반복문을 메서드 내부에 숨김으로써, 간결함을 가질 수 있었다.
사실 거창한 것처럼 말 했지만, 그냥 'forEach' 를 사용하면
내부적으론 반복문이 사용된다는 것이 그 예시이다.
아래서 부터가 좀 더 특이한 특징들이다.
2.2 중간 연산과 최종 연산

스트림의 강점 중 하나로, 스트림은 연산 결과를 스트림으로 반환한다.
정확히는 연산을 중간 연산과 최종 연산으로 나누었는데,
중간연산은 반환값이 스트림인 연산으로,
연속적으로 스트림 연산을 계속해서 적용할 수가 있다.
이런 연산 "체이닝" 덕분에 파이프라인을 구축할 수 있다.
최종 연산은 반환값이 스트림이 아니고, 스트림을 소모하는 연산으로, 마지막에 호출되어야 한다.
최종연산이 호출된다면, 스트림을 닫히게 되어 더 이상 사용할 수 없게 된다.
따라서 단 한번만 호출이 가능하다..
stream.distinct().limit(5).sorted().forEach(System.out::println);
위의 예시를 보자.
중간 연산인 distinct(), limit(), sorted()등은
몇 번이든 체이닝하면서 계속 사용이 가능하다.
그 반환이 스트림이기 때문에 이어서 계속 스트림 연산을 호출할 수 있는 것이다.
그리고 최종 연산으로 forEach가 쓰인다.
forEach를 쓰면 연산은 닫히게 되고, 연산이 종료되게 된다.
그 종류는 이 글을 참고해보자 -> 링크
2.3 "상태"와 중간 연산의 분류
기본적으로 스트림은 상태를 변경시키지 않는다고 했다.
이번에 하려는 이야기는 그런 이야기라기 보다는, 연산들이 이전 연산 정보를 필요로 하는지에 대한 이야기이다.
스트림 연산들도 stateful operation이 있고, stateless operation이 있다.
그리고 상태가 있는 연산은 다시 상태의 크기가 한정되어 있는 연산과, 한정되어 있지 않은 연산으로 나누어져 있다.(bounded, unbounded)
이걸 왜 알아야 할까 싶지만, 뒤에 다룰 스트림의 최적화 전략을 이해하는데 도움을 줄 것이다.
2.3.1 stateless operation
대표적으로 filter와 map, mapToInt, peek와 같은 연산은, 이전에 처리했던 요소들에 대한 정보가 필요없다.
그냥 원소 하나 하나 순회하면서 "지금" 이 원소의 상태 하나만 파악하면 아무런 문제가 없는 연산들을 stateless 연산이라고 한다.
2.3.2 stateful operation
상태가 있는 연산은, 순회중인 요소를 처리하기 위해 이전에 순회된 요소들에 대한 정보와 상태를 필요로 하는 연산이다.
여기서 말하는 상태는 연산의 목적에 따라 "이제까지 순회한 데이터", "스트림 구성 요소 전체" , "바로 직전에 수행된 중간 연산의 결과", "해당 연산 내부에서 자체적으로 생성하며 관리중인 값" 등 다양하다.
이렇게 상태가 있는 경우, 따로 관리를 위한 buffer가 필요할 수도 있기 때문에, 일반적인 스트림이나 병렬 스트림을 사용하는 상황에서 성능적인 손해가 있을 수 있다. 특히 일부 stateful operation은 잘못 사용하는 경우 영원히 멈추지 않는 스트림을 만들어버리거나, 지연 연산 등의 최적화에서 제외된다. (뒤에 더 다룸)
이런 상태가 있는 연산은 또 "bounded"와 "unbounded" operation으로 나뉘게 된다.
2.3.3 stateful but bounded operation
bounded 연산은 수행을 위해 관리하는 상태의 크기가 한정되어있다는 의미이다.
예를 들어 limit나 skip 같은 메서드는 정해진 갯수만큼만 수행하거나, 뛰어넘는다.
이런 경우 "정해진 갯수"에 도달했는지 셀 필요가 있는데, 이런 갯수를 저장할 상태를 보관하고 있다.
비슷하게 reduce와 같은 연산도 값을 계속해서 더해나갈 temp 변수와 같은 상태가 1개 필요한데, 이런 연산들을 동일한 개수의 상태를 가지고 있는 연산을 한정된 상태가 있는 연산이라고 부른다.
2.3.4 stateful but unbounded operation
연산을 수행하는데 있어 필요한 상태의 크기가 정해져 있지 않은 연산들을 "한정되지 않은 상태를 지닌 연산"이라고 부른다. 예를 들어 sorted는 스트림 내의 모든 데이터가 제공되어야 정렬할 수 있다. 당연한 이야기다! 전체 목록이 없는데 어떻게 정렬할 것인가? 그리고 distinct는 중복되는 값들을 쳐내는데, 당연히 값들의 리스트가 있어야 중복 여부를 확인할 수 있다.
이 때문에 두 연산을 사용할 때는 주의해야한다. 연산이 끝나지 않고 무한히 계속되는 문제가 발생할 수도 있고, 뒤에서 설명할 지연연산 최적화 대상에서 제외된다.
2.4 스트림의 지연연산!
스트림은 게으르다.
스트림은 최종연산이 수행되기 전에는 중간 연산이 수행되지 않는 다는 점이다.
정확히는, 중간 연산 과정에서 실제로 연산을 하지 않는다.
책에는 이렇게 적혀있지만,
개인적으로 더 정확한 표현은 "상태가 필요하기 전까지는 연산을 수행하지 않는다"로 생각 하는게 좋을 것 같다.
스트림의 Lazy 연산에 대해 알아보자.
분명 대부분의 연산에서는 Eager(즉시) 연산이 속도 면에서 유리하다.
한 작업의 결과가, 즉시 다음 작업의 인풋으로 쓰이는 스트림과 같은 연산이라면 그 차이가 더 클 것이다.
그리고 지연 연산 방식은 스트림 문장 전체를 인식한 이후에 시작되기 때문에, 추가 오버헤드가 발생한다.
하지만, 스트림은 Lazy한 연산을 선택했다.
이는 스트림이 거대한 컬렉션을 다루는 것을 고려해서 최적화 하였기 떄문이다.
그리고 무한한 원소를 가진 무한 스트림의 활용 또한 고려하였기 때문이다.
그게 무슨 말일까.. 스트림의 루프 퓨전과 쇼트 서킷을 보며 이해해보자.
2.5 스트림 루프 퓨~전
이름이 참 멋있다. 스트림 루프 퓨전이 무엇일까?
아래와 같은 스트림 연산이 있다.
static class Data {
private final int value;
public Data(int value) {
this.value = value;
}
@Override public String toString() {
return " -> " + value;
}
}Stream.of(new Data(1), new Data(20), new Data(300))
.peek(System.out::println)
.peek(System.out::println)
.forEach(System.out::println);- Stream.of는 입력으로 배열을 받아 스트림으로 만들어 준다.
- peek은 forEach의 유사한 중간 연산
이러한 스트림이 있을 때, 결과를 예측해보자.
-> 1
-> 20
-> 300
-> 1
-> 20
-> 300
-> 1
-> 20
-> 300당연히 위와 같은 출력을 기대할 것이다.
이것이 즉시 연산을 수행하는 eager한 연산이다.
하지만 실제로는 아래와 같이 나와버린다..

이게 뭐지..??
아아.. 이것은 루프 퓨전이라는 것이다..
예시로 보인 스트림을 for문으로 나타내면 아래와 같은 동작을 해버린다..
for (Data data : datas) {
System.out.println(data); // 첫 번째 peek
System.out.println(data); // 두 번째 peek
System.out.println(data); // forEach
}이렇게 루프를 엮어주는 루프 퓨전이 일어나면, 자료구조에서 원소들에 접근하는 횟수가 확 줄어든다!
eager한 연산으로는 분명 9번의 원소 접근이 필요한 일을 단 3번으로 줄인 것.
거대한 자료구조일 수록, 접근 횟수는 더 더욱 줄어든다. 참 신기하다!
이러한 루프퓨전이 항상 일어나는 것은 아니다.
중간 연산 중 "한정되지 않은 상태"를 사용한다면 루프퓨전이 일어나지 않을 수도 있다.
즉, 중간 연산의 결과가 필요한 경우에는 루프퓨전이 일어나지 않을 수도 있다.
어떤 연산에 있어서 이전까지의 연산 결과가 필요한 경우, 연산을 수행해 둬야 한다.
그것이 무슨 말인고... 하니, 앞서 한정되지 않은 상태 중간 연산의 예시로 언급한 sort를 생각해보자.
정렬 연산이란건, 분명히 모든 원소를 가지고 있어야 가능하다!
sort가 중간에 끼어 있다면, 당연히 그 전까지의 연산 결과를 가지고 있어야
값을 확인하고 정렬할 수 있지 않겠는가?
아래와 같은 예시를 보자.
Stream.of(new Data(1), new Data(20), new Data(300))
.peek(System.out::println)
.peek(System.out::println)
.sorted(Comparator.comparing(Data::getValue))
.peek(System.out::println)
.peek(System.out::println)
.forEach(System.out::println);- value를 확인하는 getValue를 Data에 추가로 정의해줬다.
- sorted는 값을 꺼내어 비교해준다.
위와 같은 예시가 있을 때, 2번째 peek까지는 루프 퓨전이 일어난다.
그리고 sorted를 만나게 되는데,
이 때 정렬을 하려면 당연히 연산 결과가 되는 원소들을 확인할 수 있어야 한다.
그 결과를 한대 모아 sorted해준 다음,
그 아래의 peek과 forEach에서는 다시 루프 퓨전이 다시 일어나는 것이다.
2.6 스트림 Short Circuit
쇼트 서킷이란 서킷을 끊는 것을 이야기하는데, 이름만 멋지지 우리가 조건문에서 매일 접하는 개념이다.
전류가 흐르는 서킷에 쇼트를 걸 듯, 연산을 중간에 끊어주는 행위를 말 한다.
예시를 바로 보자.
이미 잘 알겠지만, if(A == 1 && B == 2 && C == 3)이 있을 떄, A가 1이 아니라면,
그 뒤는 평가할 필요도 없이 괄호의 결과가 false이기 때문에 연산이 진행되지 않는다.
이것을 쇼트 서킷이라고 부른다.
이와 같은 행위가 스트림에서도 limit()연산을 통해 지원된다.
스트림은 빅 데이터를 다루기 위해 도입되었다.
그리고 개념적으로 무한한 원소를 갖는 무한 스트림을 이용할 때도 더러 있다.
쇼트 서킷 연산은 이러한 너무 큰 컬렉션을 다루기 위해 꼭 도입되었어야 했던 기능이였다.
예를 들어 배열 중 가장 큰 수 5개만 정렬하고 싶다고 가정하자.
Stream.generate(() -> new RandomInt())
.limit(100)
.sorted(Comparator.comparingInt(Data::getValue))
.collect(Collectors.toList());
위의 코드는 랜덤 Int 무한으로 발생하는 무한 스트림을 만든 다음 100개만을 받아서 끊어준 다음 정렬한다.
무한하게 int가 만들어지지만 limit()을 통해 필요한 만큼만 자를 수 있다.
이것이 스트림에서 지원하는 최적화 도구 쇼트 서킷이다.
가장 간단한 예를 보인거라 별로 와닿지 않을 수 있다.
limit()은 순서에 유의해야한다. 위의 순서가 바뀐다면?
Stream.generate(() -> new RandomInt())
.sorted(Comparator.comparingInt(Data::getValue))
.limit(100)
.collect(Collectors.toList());sorted에선 바로 무한한 배열의 정렬을 시도하게 된다.
무한한 배열을 정렬한다니.. 이 연산은 영원히 끝나지 않는다..
2.7 스트림 vs 반복문. 무엇을 언제 사용할 것인가?
스트림은 더욱 깔끔하고 이해하기 쉽다. 그러니까 모든 반복문을 스트림으로 처리해야할까?
질문의 말투에서 추측할 수 있겠지만, 당연히 아니다.
이펙티브 자바 Item 45에서는 스트림으로 바꾸는 것이 가능할지라도, 코드 가독성과 유지보수 측면을 꼭 고려해야 한다고 한다. 실제로는 두 측면에서 손해를 볼 수도 있기 때문이다.
그럼 어떤 기준으로 사용할지 안 할지를 결정할 수 있을까?
둘을 적절히 조합하는 것이 최선이지만, 그냥 직접 둘 다 적용해보고 더 나은 것을 고르는 것이 best라고 한다.
다만, 참고할만한 지침 정도는 있다.
아래와 같은 상황에선 스트림을 지양하자.
1. 범위 안의 지역변수를 읽고 수정해야 하는 경우.
-> 람다에서는 변화하지 않는 상태를 다루는 것이 일반적이므로 부적절
2. return, break, continue등의 세밀한 반복 제어가 필요할 때
3. 검사 예외를 던질 때
4. 다음 단계에서 이전 단계의 상태 정보가 필요할 떄 (스트림은 데이터를 버린다)
그리고 아래와 같은 상황에선 스트림이 적절하다.
1. 원소들의 시퀀스를 일관되게 변환하거나, 필터링 할 때
2. 원소들의 시퀀스를 한가지의 규칙(연산)을 사용해 결합할 때
3. 원소들의 시퀀스를 특정 컬렉션에 모을떄
4. 원소들의 시퀀스에서 특정 조건을 만족하는 원소를 찾아낼 때
2.8 병렬 스트림! - 병렬 스트림은 항상 유리한가?
스트림에는 여러 장점들이 있지만, 가장 처음 언급했듯 스트림은 빅 데이터를 위해 만들어졌고,
병렬처리를 쉽게 할 수 있게 해준다.
자바에서 병렬처리에 사용하는 fork&join 프레임워크를 내부적으로 이용하여, 우리가 알고리즘 시간에 배운 디바이드 & 컨커 방식으로, 연산을 병렬 수행해준다.
어떻게? parallel() 하나만 붙여주면 끝이다!

너무 간단하다!
parallel()은 새로운 스트림을 생성하는 것이 아니라, 스트림의 속성을 변경해주면서 쉽게 병렬화를 지원한다.
기본적으로 스트림은 스트림이 아니고, 병렬화를 취소해주고 싶으면 sequential()을 붙여주면 된다.
하지만 매우 매우 매우 매우 주의해야 할 점이 있다.
스트림은 쉽게 perallel를 적용할 수 있게 해주지만, perallel는 신중하게 고려하고 테스트 이후 사용해야 한다.
내 경험상 처음 배우는 사람은 "perallel"를 붙이면 항상 마법처럼 연산 속도가 빨라질 것이라는 기대를 한다.
하지만 그렇지 않다! 스트림 병렬화는 정말 신중하게 사용해야한다 (이펙티브 자바 Item 48)
결론만 말하자면, 연산을 잘못 사용해서 실제론 필요하지 않음에도 너무 많은 시간을 소요하는 연산을 여분의 스레드가 맡게 될 수도 있다.
이를 위한 지침은 이펙티브 자바 Item 48. 스트림 병렬화는 주의해서 사용하라에서 자세하게 다루고 있다.
간단하게 핵심 내용과 예시 하나를 언급해보겠다.

"메르센 수"란 2^n - 1 형태의 숫자들을 가리킨다.
예를 들어 1, 3, 7, 15, 31... 아마 개발자들에게는 매우 익숙한 숫자일 것이다.
그리고 "메르센 소수"란 이 메르센 수 중에 소수(Prime)인 것을 가리키며,
메르센 수 2^n - 1이 소수인 경우, n 또한 소수인 재미있는 특징을 가졌다.
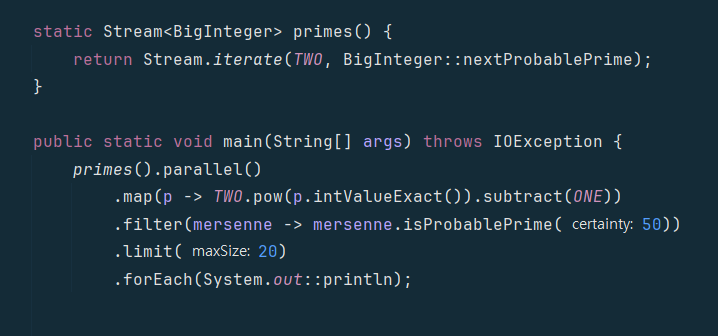
위 코드는 스트림을 활용한 메르센 소수를 생성하는 프로그램이다.
메르센 소수는 계산 비용이 높기 때문에, 스트림 parallel을 활용했다.
위 코드가 어때 보이는가? 위 코드는 평범하게 생겼지만 실제로는 거의 무한한 루프를 돌게 만드는 악마적인 코드이다.
중간 연산으로 Limit를 쓰거나, 데이터 소스가 Stream.iterate라면 병렬화를 통한 성능 개선이 불가능하다.
위 코드는 두가지 모두에 해당한다.
스트림 iterate는 무한 스트림을 만들어낸다. 그렇기 때문에, 연산을 끊어주는 무언가가 필요하고, Limit와 자주 쓰인다
문제는 크기가 무한하고, 이전 결과를 활용해 다음 결과를 만들기 때문에, 때문에 중간 지점을 알기 어렵다.
스트림 라이브러리는 itreate의 파이프라인 병렬화 방법을 알아내지 못한다.
2.8.1 중간연산 Limit는 왜 문제가 되는가?
또 파이브라인 병렬화 중에 사용되는 중간 연산 Limit 사용은 주의해야 할 점이 있다.
CPU 코어를 좀 더 효율적으로 사용하기 위해, 남는 CPU 코어가 있다면 일단 연산을 할당하고, Limit 제한에 맞게 결과를 버린다.
예를 들어 코어가 8개이고, Limit 가 20이라고 생각해보자.
이 경우 8개의 코어가 각각 2번 연산을 진행했다고 하면, 이제 4개의 연산이 남는다.
Limit는 이때 4개의 코어만 사용하지 않고, 일단 8개의 코어에 모두 연산을 할당한다.
불필요한 4번의 연산이 더 생기는 것이다.
여기서 문제는 메르센 소수 연산이 매우 매우 무거운 연산이라는 것이다.
메르센 소수 연산은 k + 1번째 메르센 소수를 찾을 때 k번째 메르센 소수를 찾는데 걸리는 시간 보다 무려 2배의 시간이 더 소요된다. 예를 들어 막 32번째 메르센 소수를 찾았고, 4개의 메르센 소수를 더 찾아야 한다고 생각해보자. (36개가 목표)
이때 33 ~ 40 번째 메르센 소수를 찾는 연산이 코어들에 할당되고, 불필요한 4개의 연산이 추가된다.
문제는 뒤의 불필요한 4개에 소요되는 시간이 무지막지하다!
37, 38, 39, 40번째 연산은 각각 36번째 연산 소요 시간의 2배, 4배, 8배, 16배의 시간이 걸리게 되는 것이다.
첫 메르센 수를 찾는 시간을 t라고 할 떄, k번째 메르센 소수를 찾는 시간은 t * (2^(k - 1))라고 할 수 있을 것이다.
뒷부분의 2의 제곱들만 보자. 2진수의 특성상 k번째 까지의 2진수를 모두 더하면, 다음 2진수 보다 1만큼 작은 수가 된다.
그러니까 불필요한 4개의 연산중 첫번째 연산 부터가 이제까지의 모든 연산을 합친 것 보다 더 오랜시간이 걸린다.
그런 행동을 3번이나 더 하니 얼마나 끔찍한 일인가..
무서운 일이다. 그래서 병렬화는 언제 어떻게 쓰는게 효과적인걸까?
2.8.2 언제 스트림 병렬화가 효과적일까?
세 가지 기준으로 나누어 보자.
1. 연산량
2. 자료구조
3. 연산 종류
2.8.2.1 연산량 기준
위에서 언급한 절대 사용하면 안되는 사례를 모두 피했다고 가정하고, 연산량만을 기준을 생각해보자.
병렬화에도 결국 추가적인 오버헤드가 든다. 작업을 디바이드 엔 컨커를 통해 분할하고 합치고.. 코어와 스레드를 할당하고.. 풀을 사용하더라도 결국 Run 상태인 스레드가 늘어나는 것이고 동기화, 컨텍스트 스위칭.. 각종 리소스 사용
등! 각종 오버헤드가 있기 때문에, 병렬화 적용 이후 직접 테스트 해봐야 실제로 효과가 있는지 확인할 수 있을 것이다.
이펙티브 자바에서는 연산량이 수십만 이상인 경우 부터 적합하다고 말한다.
원소에 수행되는 연산수들을 가늠해서 최소 수십만은 되어야 성능 향상에 유의미한 효과가 있다고 한다.
2.8.2.2 자료구조 기준
자료구조를 기준으로 병렬화에 유리한 상황을 생각해보면
1. 나누기 쉽고
2. 참조 지역성이 높으면 좋다.
왜냐하면, 아까 언급했듯 내부적으로 포크 조인 프레임워크에 의한 분할 정복 방식으로 잡을 나누기 때문에, 나누기 쉬울 수록 좋고, 연속적으로 배치 되어 있어 데이터 위치를 특정하고 가져오는 비용이 낮을 수록 좋다.
그러한 자료구조의 예시는 아래와 같다
1. 배열과 ArrayList (배열 기반이라서)
2. HashSet, HashMap, ConcurrentHashMap
2.8.2.3 종단 연산의 종류
종단 연산의 종류로는 "축소" 연산 혹은 "조건에 따라 하나 반환"하는 연산이 좋다.
예를 들어 reduce, min, max, count, sum
이들은 많은 원소들에서 더 적은 갯수의 결과를 만든다
결국 내부적으로 분할 정복을 사용하므로, 분할된 범위들을 합치는 과정이 매우 빠를 것이다.
예를 들어 max를 구할 때 k번째 범위와 k+1번째 범위를 합치는 과정이 O(1)일 것이다. 단순히 더 큰 값을 저장하면 되기 때문이다. sum도 count도 단순히 합치면 되기 때문에 연산이 빠를 것이다.
(세그먼트 트리를 활용하는 방법과 비슷하게 생각하면 좋을 것 같다.)
적합하지 않은 연산으로는 컬렉션들을 합치는 collect와 같은 메서드들이다.
분할 정복 과정을 생각하보면 합치는 과정에서 많은 연산이 발생할 수 밖에 없다. 합치는 부담이 크다. 이를 회피하고 싶다면 spliterator를 Override하는 방법이 있는데, 이 방법은 이펙티브 자바 item 42를 참고하자.
2.8.3 왜? 왜? 병렬화를 사용하려 하는지 "왜?"에 집중!
결국 "왜" 사용하는지에 집중해야 한다.
성능 아닌가? 단지 쿨해서, "빠를 것으로 기대되서", 이력서에 나 병렬화 했어요라고 쓰기 위해서 파이프라인 연산들의 특징과 병렬화의 특징을 모른채 그냥 사용한다면 오히려 성능에 나쁜 영향을 미칠 수 있다.
결국 성능 아닌가? 위에 언급한 주의사항들을 고려하며 꼭 전후로 테스트를 시행하여 제대로 효과기 있는지 확인해야 할 것이다!
2.10 마무리 - 스트림을 위한 람다와 선언적 프로그래밍!
결국
데이터!를 제대로 다루기 위한
컬렉션!을 효율적으로 사용하기 위한
스트림!을 위한
함수형 프로그래밍!을 위한
것이 람다!라는 것이다.
그럼 스트림, 람다를 사용하면 뭐가 좋을까?
정말 여러가지 장점을 보았지만, 함수형 프로그래밍의 장점인 선언적 프로그래밍을 활용할 수 있게 된다!
코드를 짜는 사람과 읽는 사람 모두 How가 아닌 What에 집중할 수 있게 된다!
무엇을 어떻게 해주세요~가 아닌, 무엇을 줘!가 됩니다.
마지막으로 짧은 반복문 코드의 리펙토링 과정을 보자
음식의 칼로리가 1000 초과면 식탁에서 나가달라고 소리치는 예제이다.

이건 너무하니까 향상된 for 문을 적용

보기 좀 나아졌다.
하지만 더 복잡한 for문이였다면 이정도로는 택도 없었을 것이다.
람다 + 스트림을 적용해보자

정말 선언적이다!
- foods에서 칼로리만 꺼내 mapping해줘.
- 배열에서 1000 칼로리 초과인 선별(filter)해줘.
- 선별된 요소들의 칼로리를 외치며 저리 가라고 말해줘.
코드를 보면 마치 SQL문 처럼 오로지 내가 무엇을 원하는지만 요구했다!
기존에는 어떻게 해야 했는가?
ages 배열을 하나하나 순회하면서... age를 꺼내고..
그 age의 value가 20 미만일 경우엔.. 무언가를 출력하고..
이런 방식보다 훨씬 직관적이고 깔끔하다!
선언적 프로그래밍 요소 덕분에 객체간 의사소통 내용 그 자체가 그대로 코드로 구현되었다.
람다와 스트림을 알고 쓸 수 있는 의의는 선언적 프로그래밍을 통해 더욱 읽기 좋고 의존성이 낮은 프로그래밍을 가능하게 해주며, 컬렉션을 보다 쉽게 다루고, 상황에 따라 최적화하거나, 실수로 오히려 느리게 만드는 일을 최대한 없앨 수 있다.
이 글이 재미있었길 바란다!
평소 생각 없이 쓰던 람다와 스트림을 파보니 그 안엔 정말 재미있는 세상이 있었고
여러분도 그 재미를 느꼈으면 하는 마음에 이렇게 글을 작성해보았다.
Reference
- bugoverdose님 블로그
- 자바의 정석 2권 <남궁민 저>
- 스프링 입문을 위한 자바 객체지향
- 모던 자바 인 액션 <라울-게이브리얼 우르마>
- 이펙티브 자바 <조슈아 블로크>
'🌱 Java & Spring 🌱' 카테고리의 다른 글
| Java 인터페이스의 OOP적인 활용 (0) | 2023.07.20 |
|---|---|
| 자바의 Type에 대해 (0) | 2023.06.15 |
| 바이트 코드를 JVM에 싸서 드셔보세요 (0) | 2023.05.24 |
| Bucket4J 사용하는 법 자세히 알랴드림 (0) | 2023.03.20 |
| [Spring] Template Callback Pattern in Spring (0) | 2022.10.14 |